 Товаров:
Товаров:
- 1. Jak zainstalować Screaming Frog
- 100% bezpłatny kurs SEO.
- 3. Tryb Pająk
- 3.1 Zewnętrzne
- 3.2 Protokół
- 3.3 Kody odpowiedzi
- 3.4 URI
- 3.5 Tytuł strony
- 3.8 Etykieta H1
- 3.9 Etykiety H2
- 3.10 Obrazy
- 3.11 Dyrektywy
- 3.12 Etykiety Hreflang
- 3.13 AJAX
- 3.14 Niestandardowe
- 3.15 Analytics
- 3.16 Konsola wyszukiwania
- 4. Tryb listy
- 5. Tryb SERP
- 6. Dodatkowy utwór
- 7. Inne narzędzia Screaming Frog
Chcesz dowiedzieć się, jak zoptymalizować SEO na swojej stronie internetowej jak profesjonalista? Screaming Frog Seo Spider to najlepsze narzędzie na świecie do analizy na stronie adresy internetowe , Jest to scrapper, pająk, który sprawdza sieć od góry do dołu, link po linku i analizuje go, pokazując wszystko, co chcesz wiedzieć o każdej ze stron.
Mówi ci, ile znaków tekstowych ma każda strona, jej wewnętrzne i zewnętrzne linki, metadane ... Sprawdza wszystko, więc idealnie nadaje się do poprawiania błędów, poprawiania architektury witryny, a tym samym do poprawy pozycjonowania organicznego.
W tym przewodniku „Krzycząca żaba” wyjaśniam krok po kroku, jak działa narzędzie i wszystko, co można analizować.
1. Jak zainstalować Screaming Frog
Krzycząca Żaba jest niezbędnym narzędziem i, w przeciwieństwie do innych, jest aplikacją komputerową, a nie online, więc musisz pobrać ją na swój komputer z Sekcja SEO Spider z głównego menu swojej strony internetowej, aby go użyć.
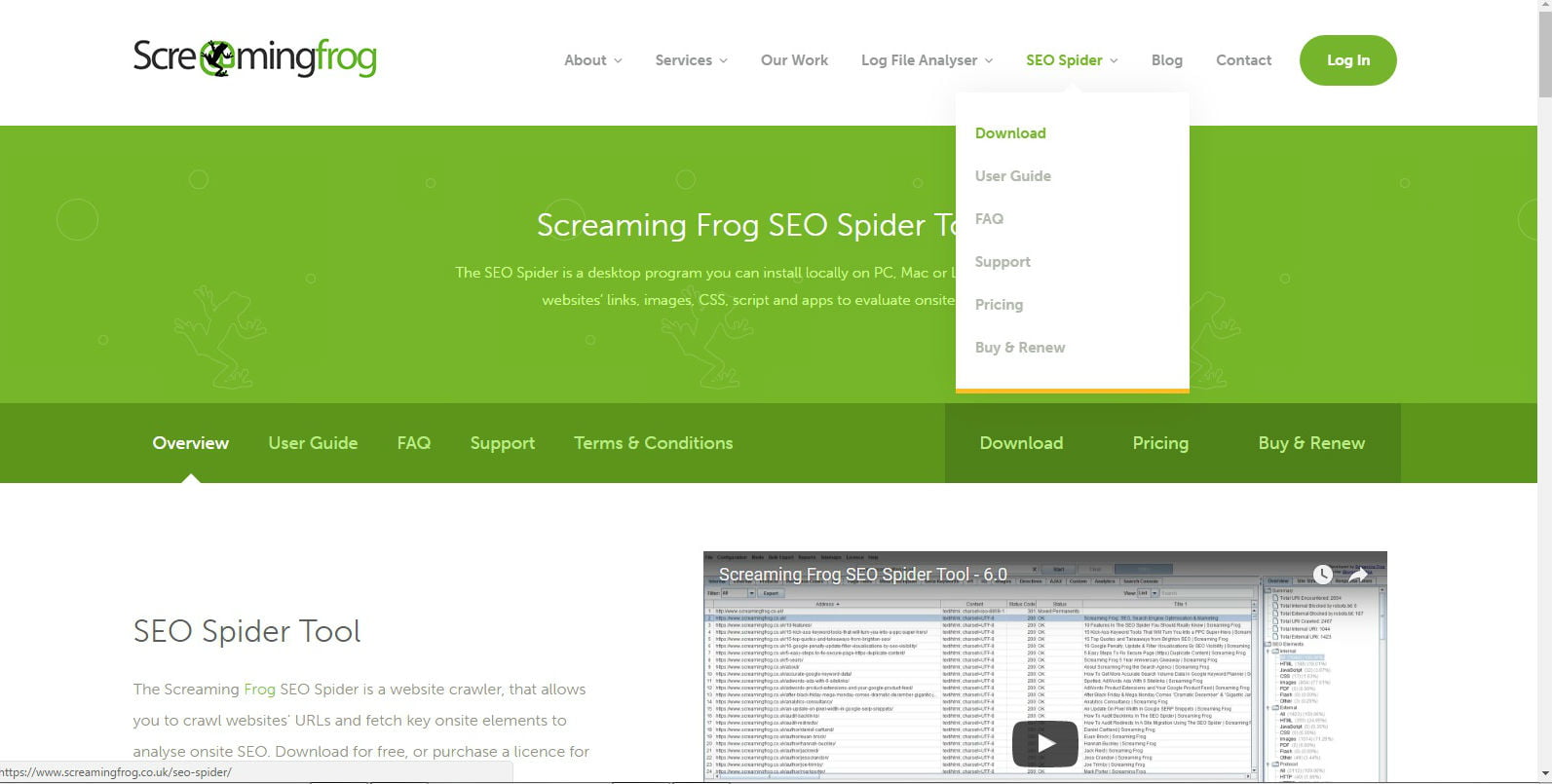
Posiada darmową wersję, za pomocą której możesz analizować do 500 adresów URL, ale aby zapisać projekty i uzyskać dostęp do wszystkich funkcji, musisz kupić roczną licencję, która kosztuje 149 funtów, przy obecnym kursie wymiany 172 euro. Są mniej niż 15 euro miesięcznie i warto.
100% bezpłatny kurs SEO.
- Utwórz stronę zoptymalizowaną pod kątem SEO
- Zwiększ ruch dzięki bezpiecznym strategiom
- Zarabiaj z nią pasywne pieniądze
Po podjęciu decyzji, której wersji będziemy używać, przejdziemy do pobierania.
W tym samouczku Streaming Frog wersja narzędzia to 7.2. Możesz zostać poproszony o zaktualizowanie kodu JavaScript komputera, aby go uruchomić i uruchomić.
Cóż, kiedy już go otworzyliśmy, znaleźliśmy jego główny interfejs, który, jak widać, jest dość surowy.
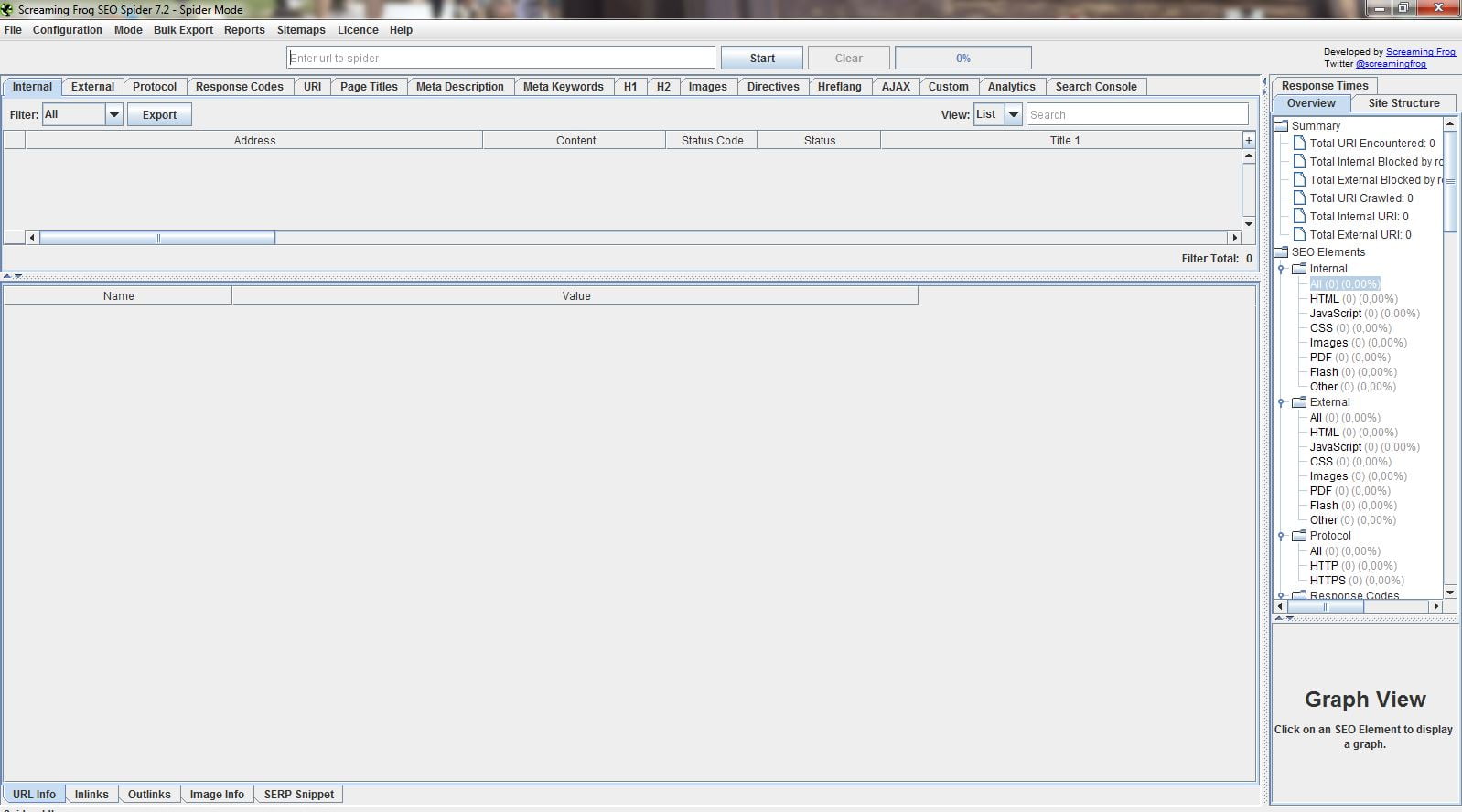
Zacznijmy od tego, co oferuje górne menu w sposób domyślny, czyli Spider, czyli pająka.
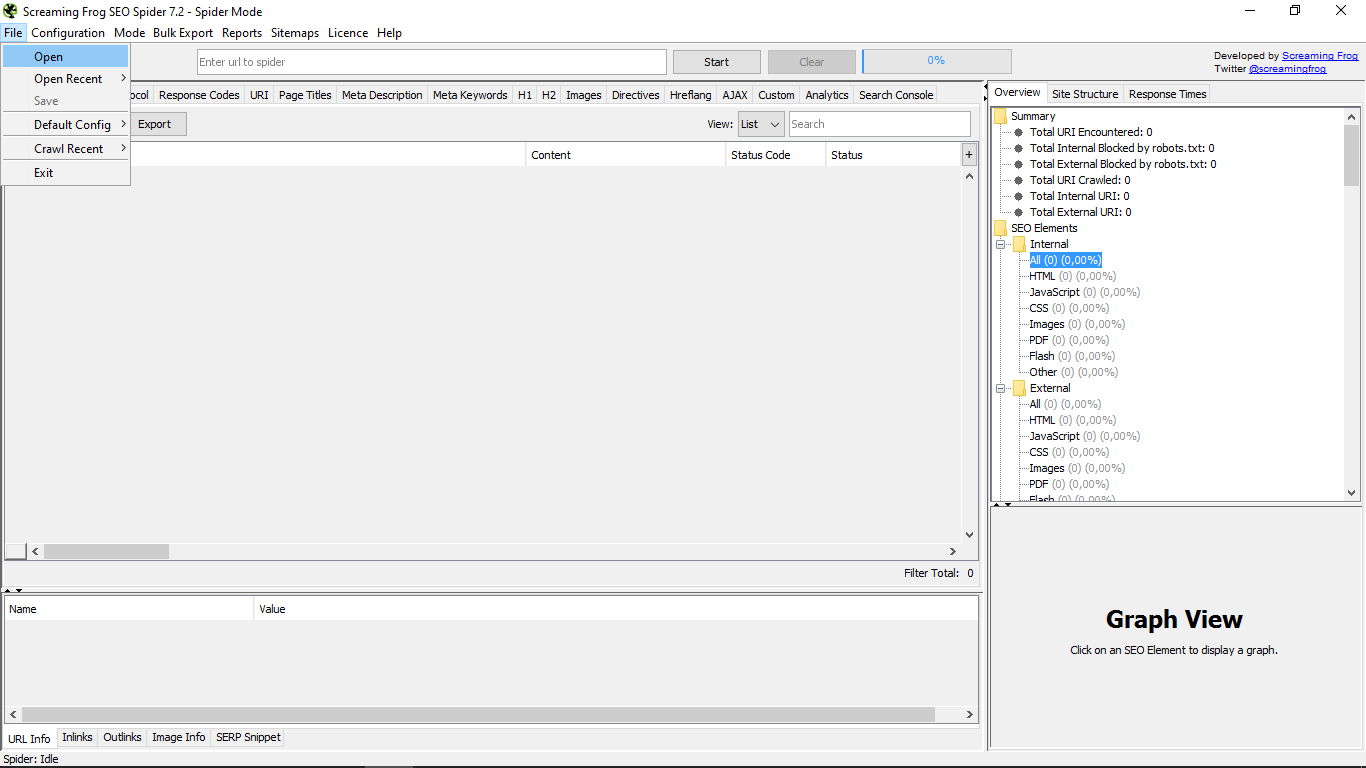
W menu „Plik” możemy otwierać pliki z dowolnej lokalizacji, ponownie otwierać najnowsze i zapisywać je. Możemy również „nagrać” konfigurację, która w tych momentach mamy jako tę, która domyślnie pojawi się zawsze lub usunie istniejącą. Możesz także wyczyścić „indeksowanie” lub niedawne indeksowanie i na koniec opuścić narzędzie.
W „Konfiguracja” mamy podmenu „Pająk”, które daje nam możliwość wskazania, jak chcemy, aby pająk działał na stronach, które chcemy analizować.
Istnieje wiele czynników, które możemy dostosować w zależności od tego, co nas interesuje w każdym przypadku.
Tutaj mamy na przykład w nagłówku HTTP opcję User Agent, która pozwala nam zdecydować, z jakim typem „pająka” będziemy pracować.
Jest to przydatne, gdy hosting, na którym hostowaliśmy naszą stronę, blokuje dostęp do pająka Screaming Frog i nie możemy użyć tego narzędzia. Po prostu użyj symulatora robota Google, aby rozwiązać problem.
W „Robots.txt” możemy skonfigurować, a także dostosować sposób, w jaki pająk będzie się zachowywał przy tego typu plikach.
W pozostałych opcjach mamy bardzo zróżnicowane funkcje konfiguracyjne, w tym połączenie z interfejsami API Analytics i Search Console lub wizualizację interfejsu nieco bardziej przyjazną, w stylu Windows. Będziemy pracować z nią nad tym przewodnikiem Screaming Frog, ponieważ jest bardziej uporządkowany i intuicyjny.
W „Trybie” wybierzemy główną funkcję, z której chcemy korzystać: spider, list lub SERP. Następnie wyjaśnimy je szczegółowo, ponieważ ogólne menu różni się w każdym przypadku.
„Eksport zbiorczy” pozwala nam masowo eksportować w dokumentach w formacie CSV raporty dotyczące przychodzących lub wychodzących łączy, obrazów, tekstu zakotwiczenia, a także dostosowywać filtry; w „Raportach” uzyskamy dostęp do podsumowania śledzenia i raportów o błędach w różnych parametrach.
„Mapy witryn” umożliwiają nam tworzenie mapy witryny, a także zdjęć. Opcje te są obecnie rzadkie, ponieważ zawiera większość narzędzi do zarządzania siecią. Jeśli tak nie jest, możesz pobrać je tutaj i wysłać do Google Search Console.
„Licencja” jest linkiem do zapłaty za wersję „pro” i wprowadzenia hasła po subskrybowaniu.
W „Pomocy” mamy wreszcie podręcznik użytkownika, kilka często zadawanych pytań, pomoc techniczną i kontakt zwrotny, wyszukiwanie i automatyczne sprawdzanie aktualizacji narzędzi, debugger debugowania i stronę „Informacje”. Pomoc, której mamy nadzieję nie trzeba używać po przeczytaniu tego samouczka 😉
3. Tryb Pająk
Będąc w tej modalności narzędzia, jeśli wprowadzimy adres URL strony, przeprowadzimy pełny audyt witryny.
Jest pasek postępu, który wskazuje procentowo postęp „skanowania” wszystkich omawianych stron internetowych, jak widać na poniższym zrzucie ekranu. Istnieje możliwość zatrzymania procesu, a następnie wznowienia lub bezpośredniego usunięcia zapytania.
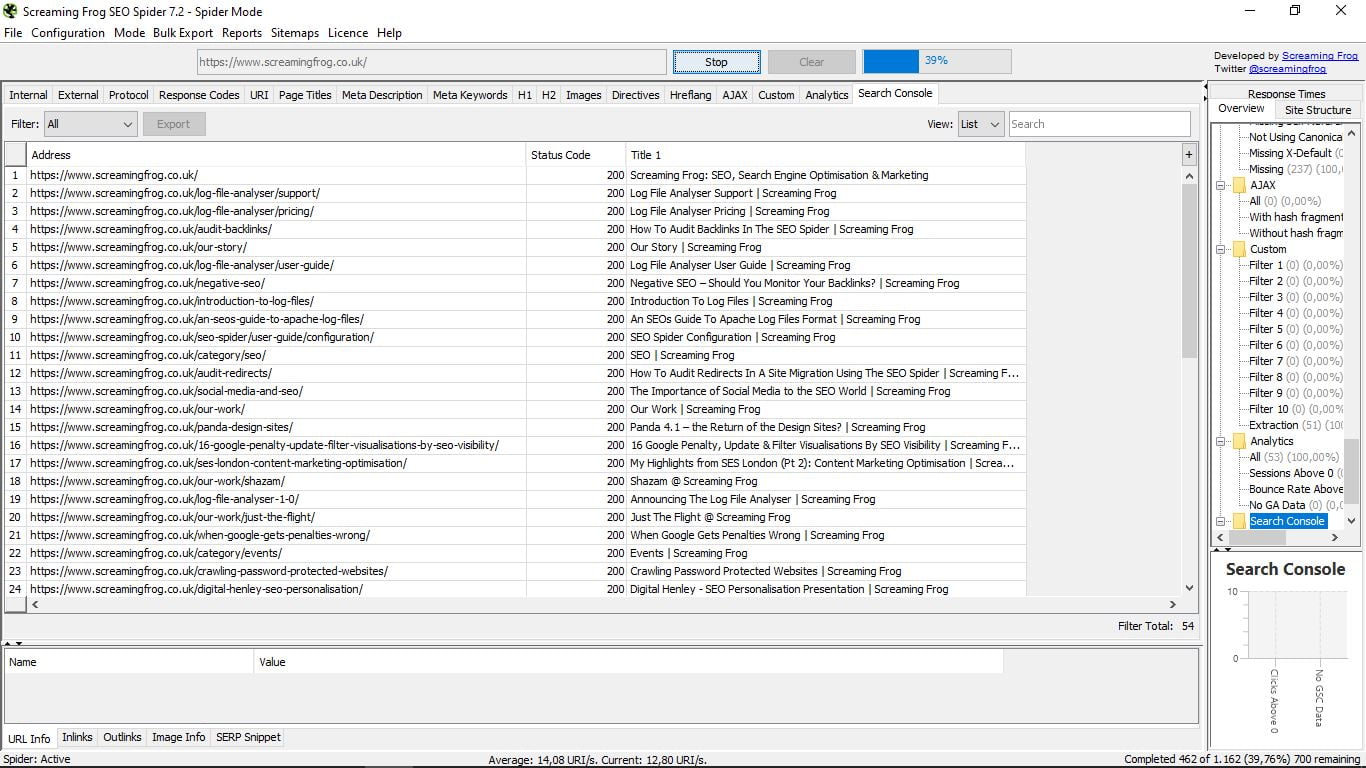
Zobaczmy stronę internetową Screaming Frog.
Gdy zadanie pająka zostanie zakończone (zajmie to mniej lub więcej w zależności od rozmiaru sieci), poznamy całkowitą liczbę stron, które są częścią Twojej witryny. W tym przypadku są one 3 045. Ze wszystkich widzimy teraz niekończące się dane.
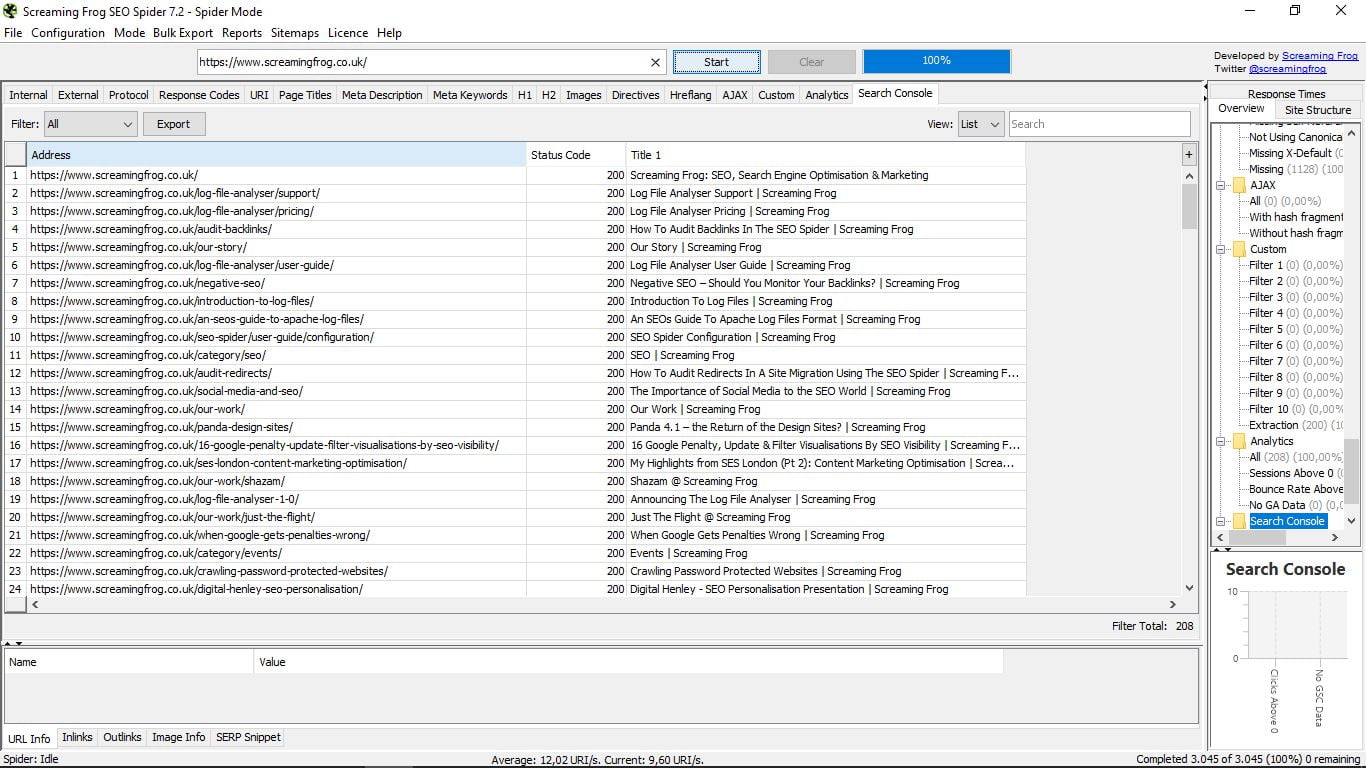
Mamy domyślną opcję, aby pokazać wszystko, ale w „Filtruj” (w lewym górnym rogu okna wyników) możesz filtrować strony według typu zawartości, jaką są: html, JavaScript, CSS, pdf, obrazy, flash ... Można wyeksportować dowolne z tych selektywnych wyszukiwań lub ich sumę (przycisk Eksportuj)
Po prawej stronie w „Widoku” możemy wybrać widok według listy lub drzewa folderów, a także wykonać w pasku „Wyszukaj” wyszukiwanie według słów, aby zlokalizować określony adres URL.
W tabeli można również sortować wyniki według typu treści, kodu statusu i tytułu.
Kiedy klikamy na konkretny adres URL, widzimy, że poniżej możemy rozwinąć okno, w którym podaje nam wszystkie informacje na jego temat:
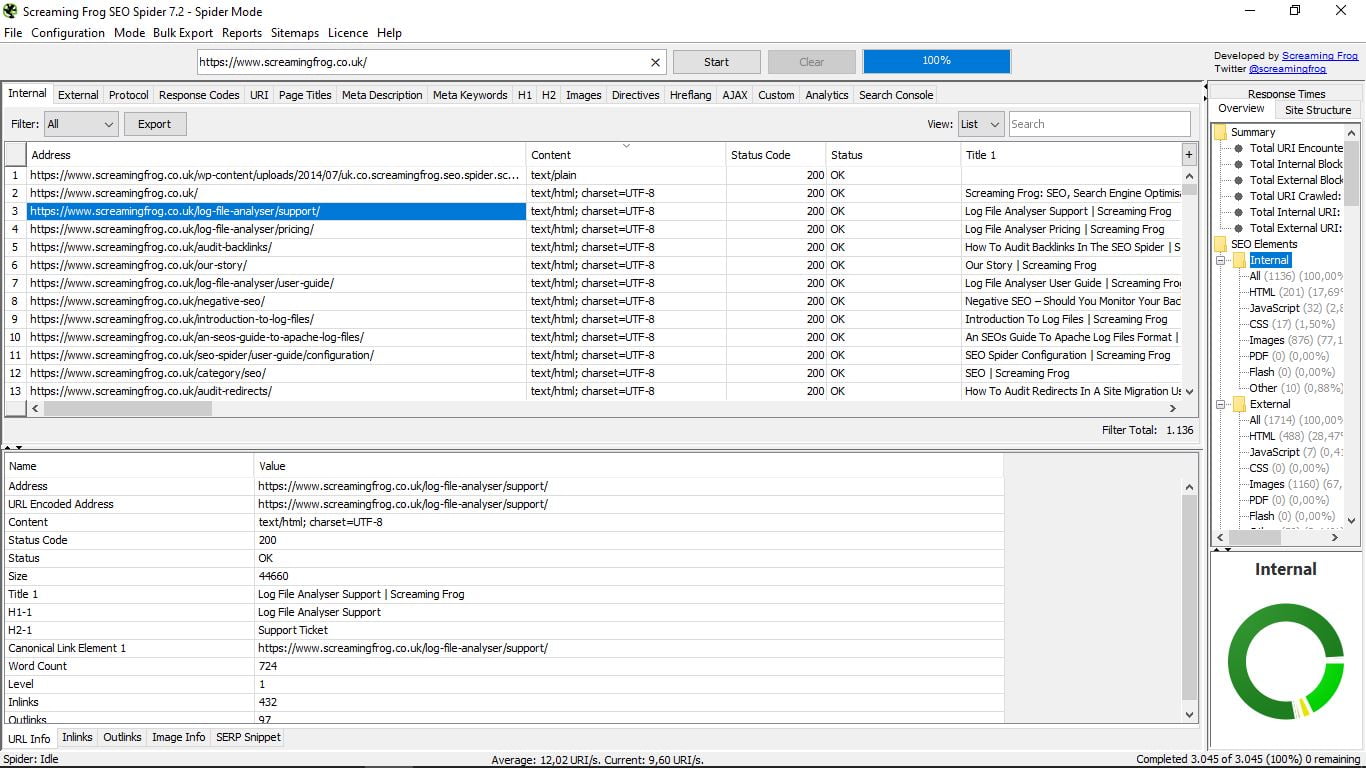
W tym samym oknie mamy inne podmenu, które pozwala wybrać rodzaj wyświetlanych danych:
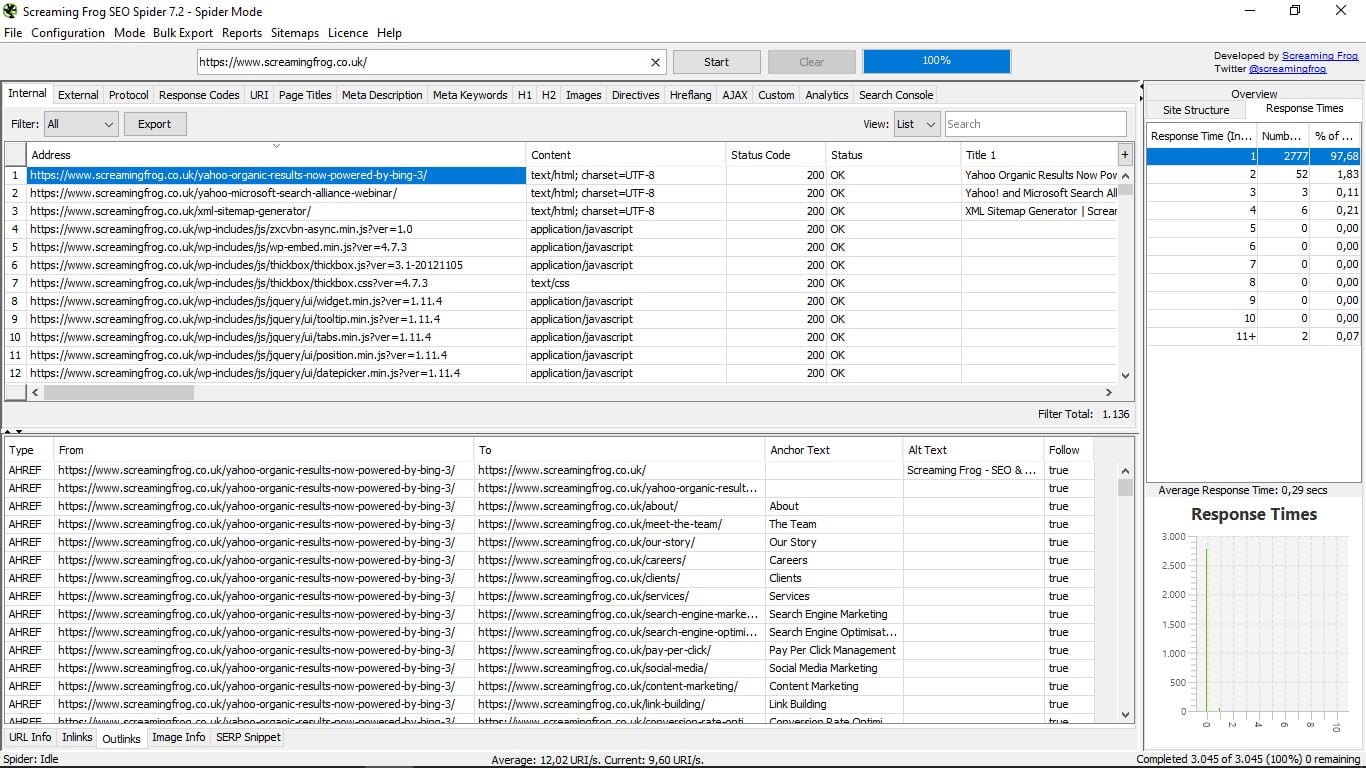
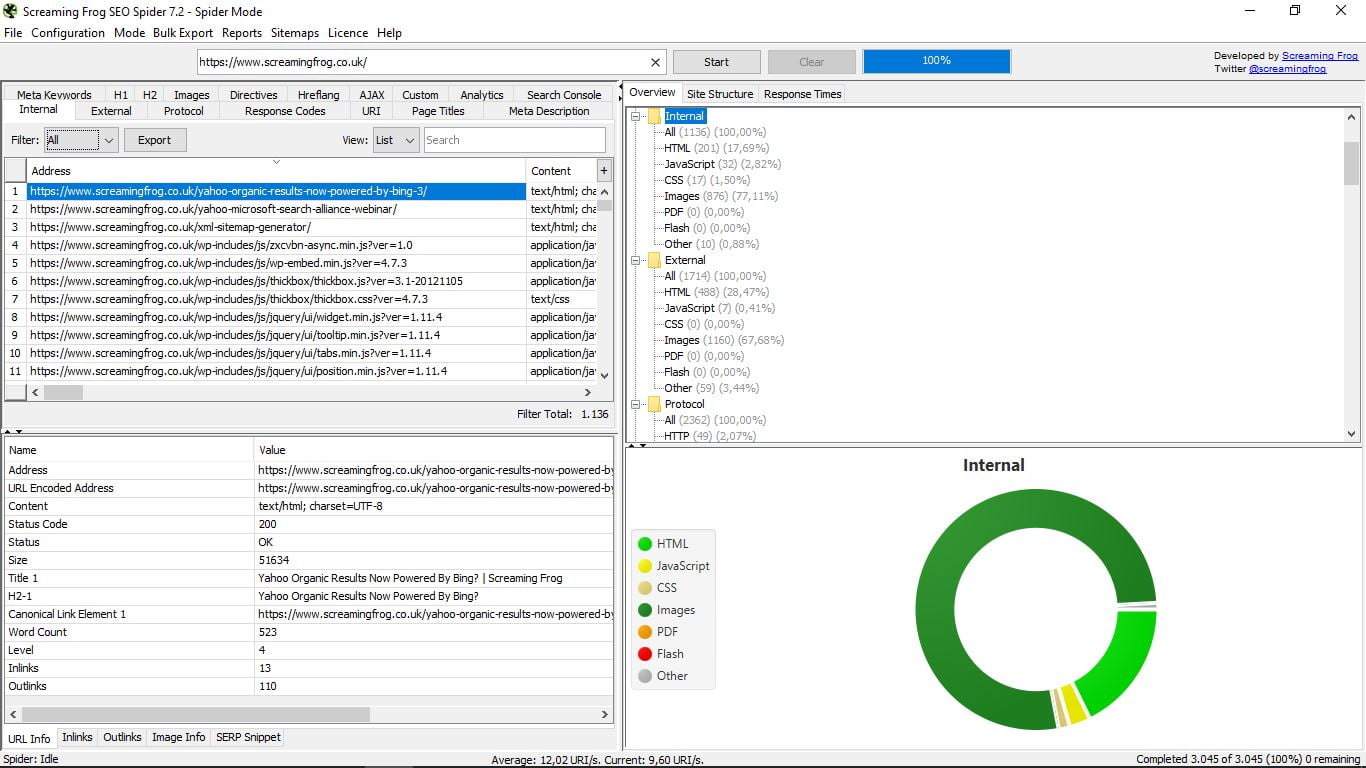
- Informacja o adresie URL, która jest domyślna i podaje adres, typ treści, stan, rozmiar, tytuł, pierwszy H2, link kanoniczny, liczbę słów, poziom, liczbę linki wewnętrzny i zewnętrzny.
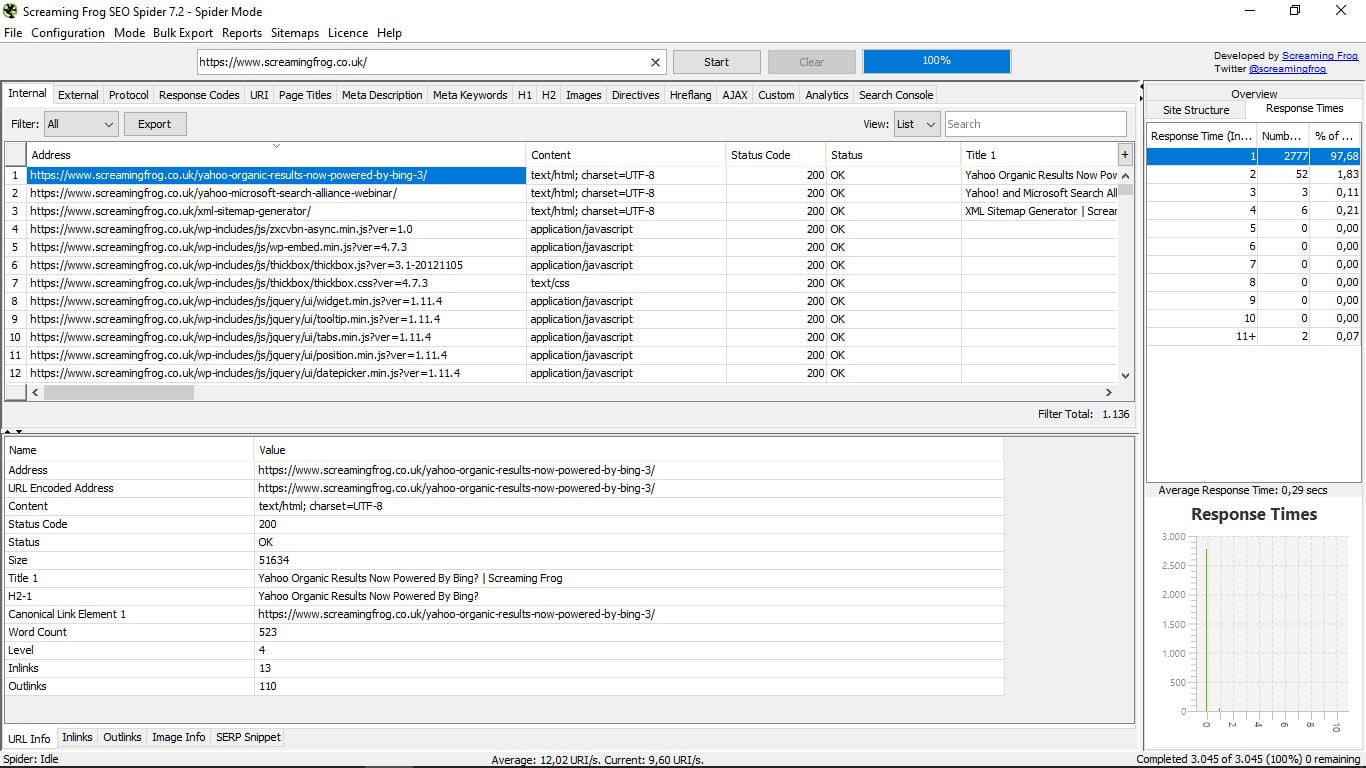
- Linki (linki wewnętrzne), które pokazują nam rodzaj łącza, gdzie idziesz i dokąd idziesz kotwica tex t, tekst Alt (jeśli go posiada) i czy są one podążane, czy nie.
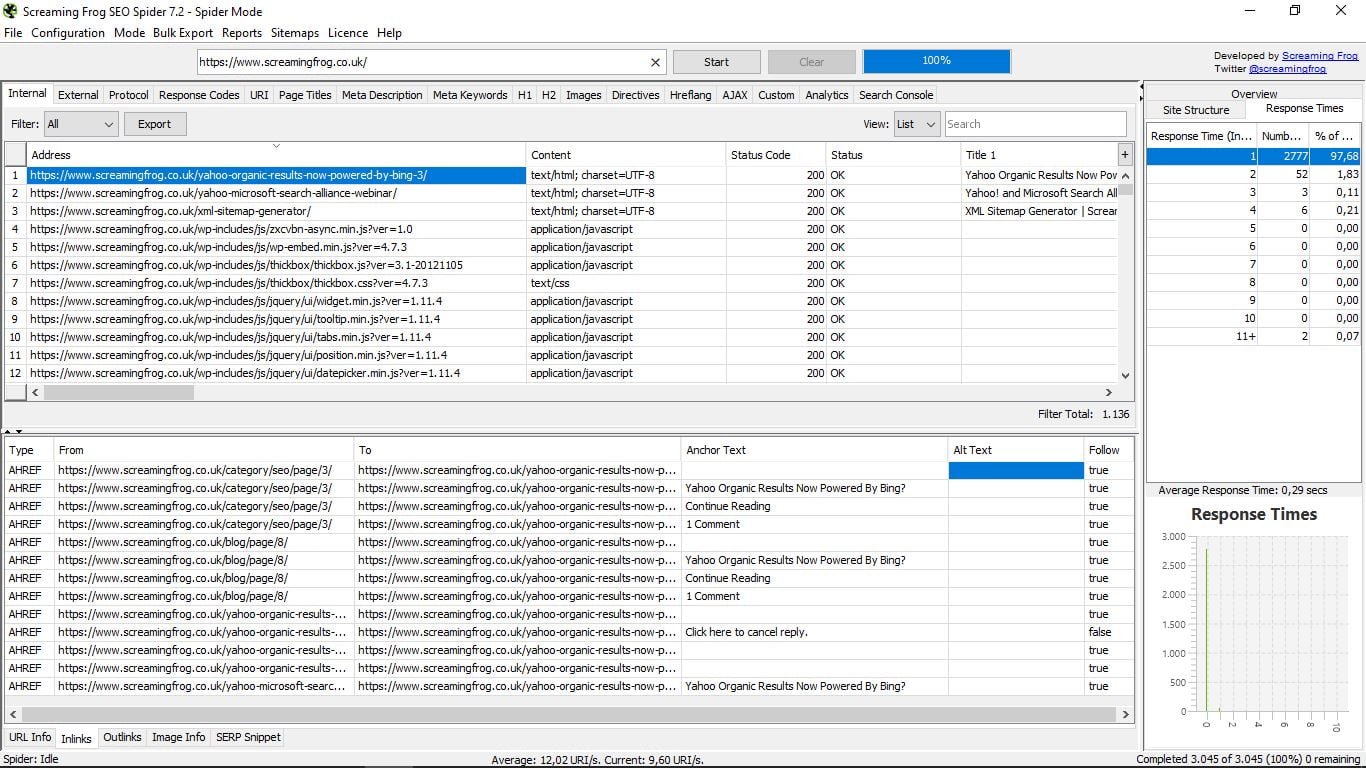
- Outlinks. Dokładnie te same informacje, co w łączach, ale dla linków zewnętrznych.
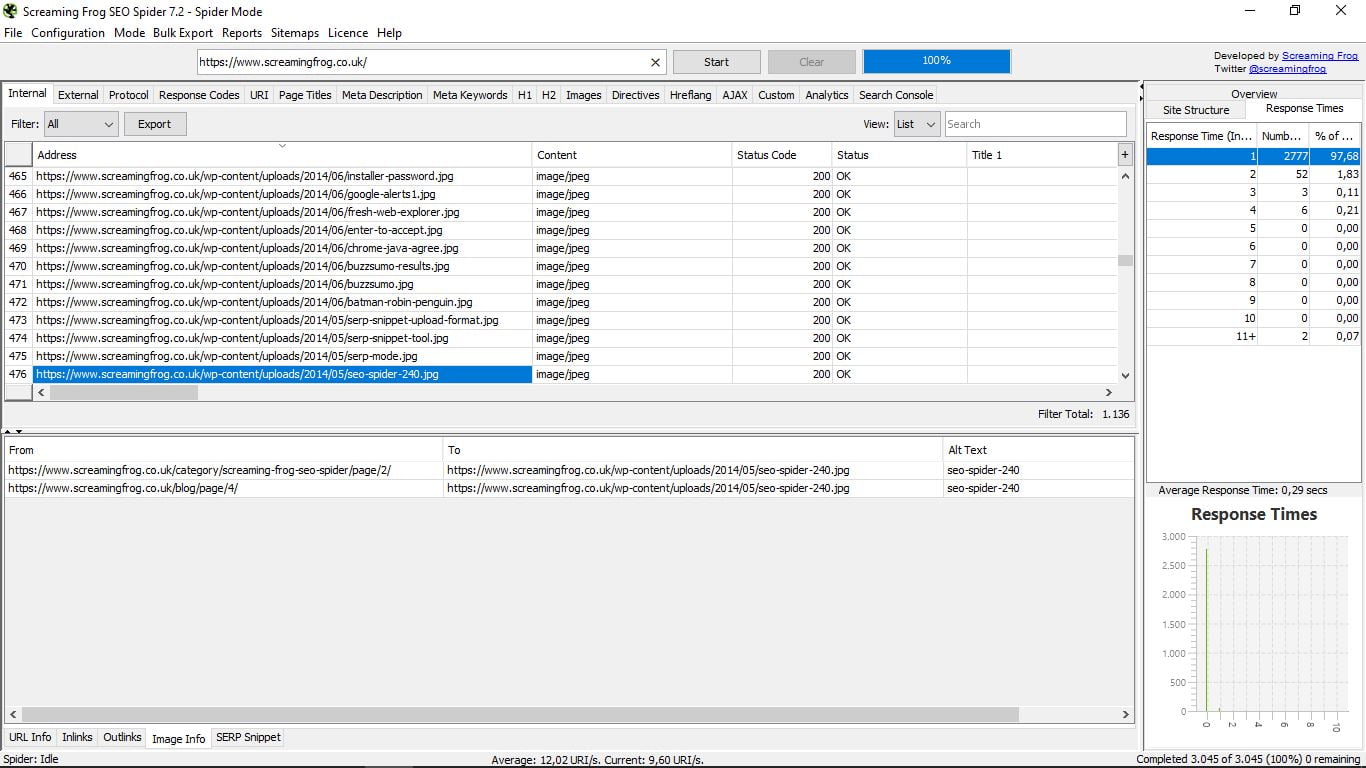
- Informacje o obrazie: informacje o połączonych obrazach zawartych na tej stronie, gdzie wskazuje i tekst Alt.
- Urywek SERP. Zobacz, jak wygląda ta strona w wyszukiwaniach Google. Pozwala to zobaczyć na pulpicie, telefonie komórkowym i tablecie i zawiera symulator, z danymi postaci i pikseli dla tytułów i opisów, słów kluczowych, Bogate fragmenty (Recenzje, ludzie, wydarzenia), z gwiazdami lub bez ...
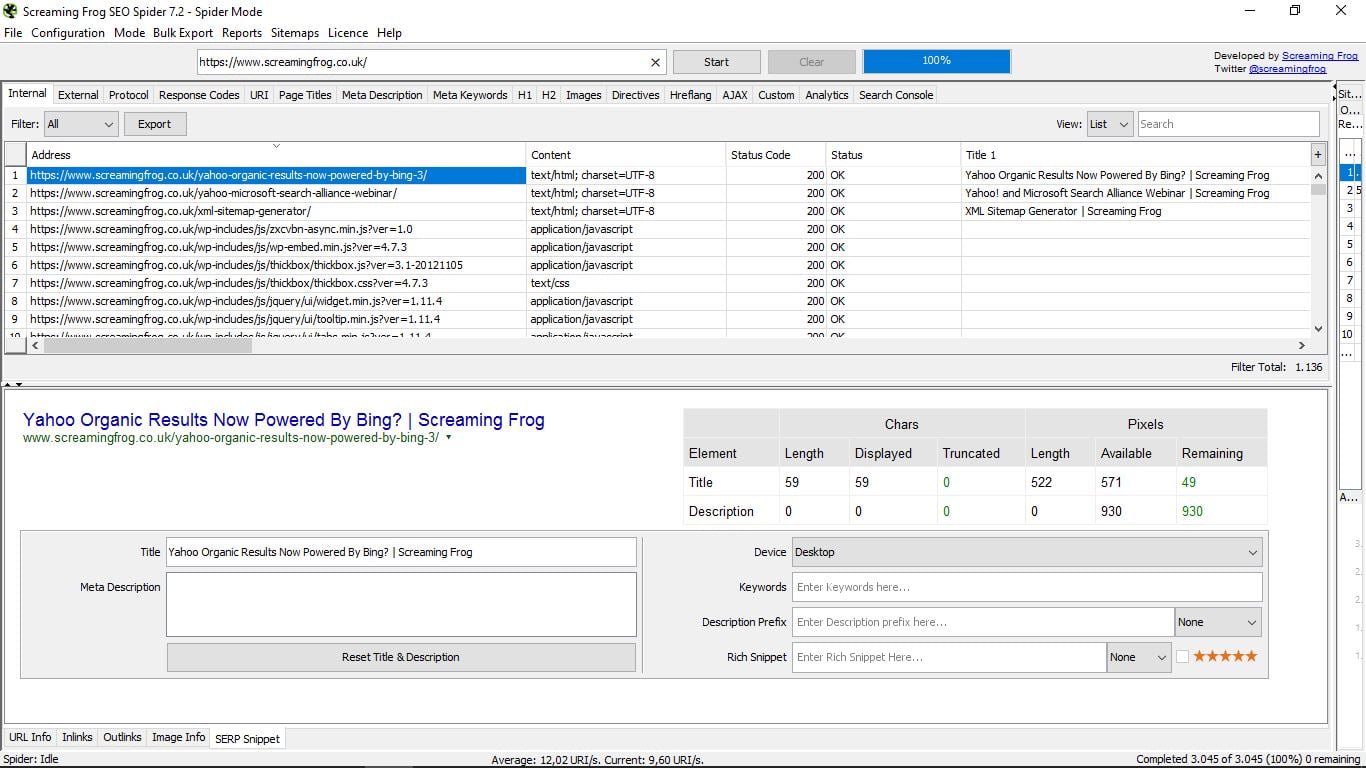
Do tego wszystkiego, jeśli zauważysz, po prawej stronie aplikacji, w wąskiej kolumnie, którą można rozszerzyć, mamy trzy opcje, które zawsze możemy rozważyć podczas konsultacji.
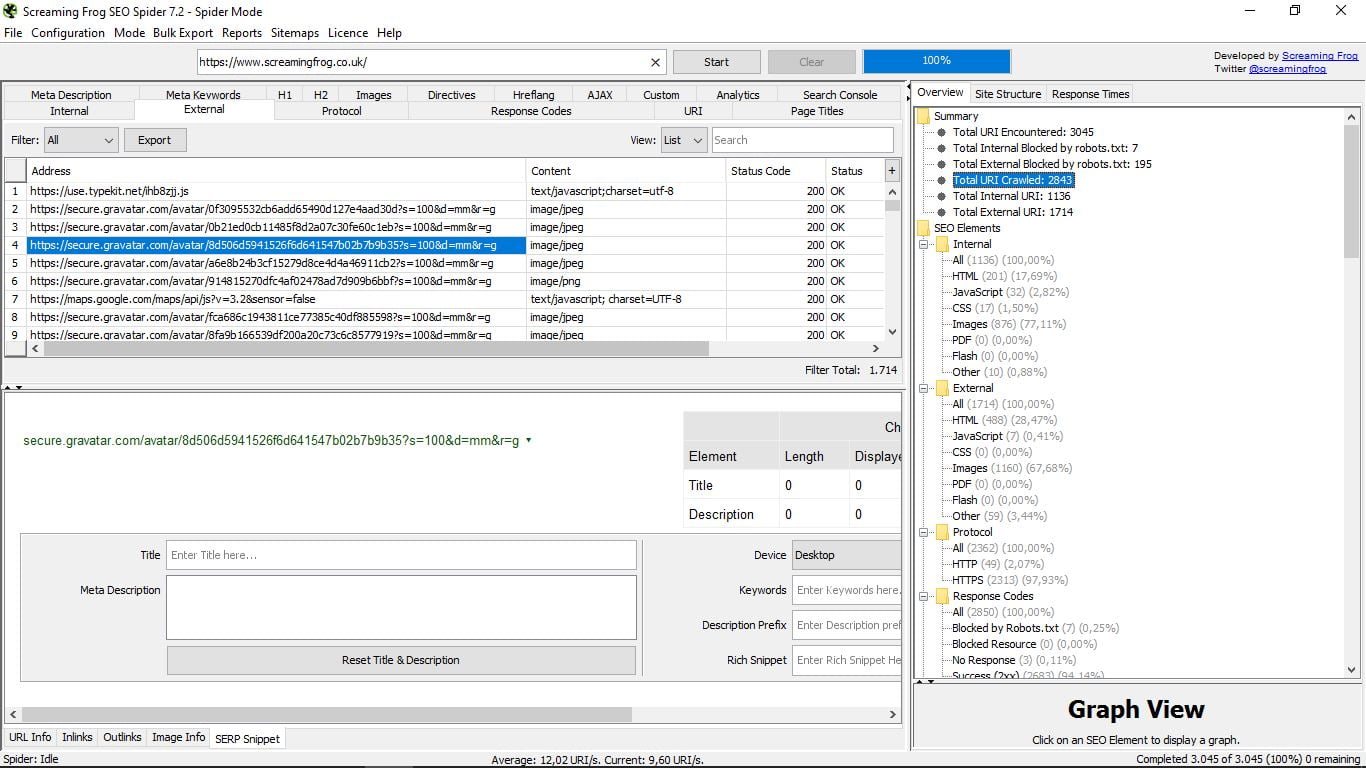
- Przegląd, ogólny widok w formacie drzewa z folderami i podfolderami, który pokazuje w każdym przypadku różne składniki każdej szukanej informacji, wraz z całkowitą liczbą i procentem. Na przykład bycie w Internal mówi nam, jak widać na zrzucie ekranu, że jest w sumie 1136 stron, z których 200 to HTML i stanowią 17,69% całości; obrazy są 876 (77,11%), itd ...
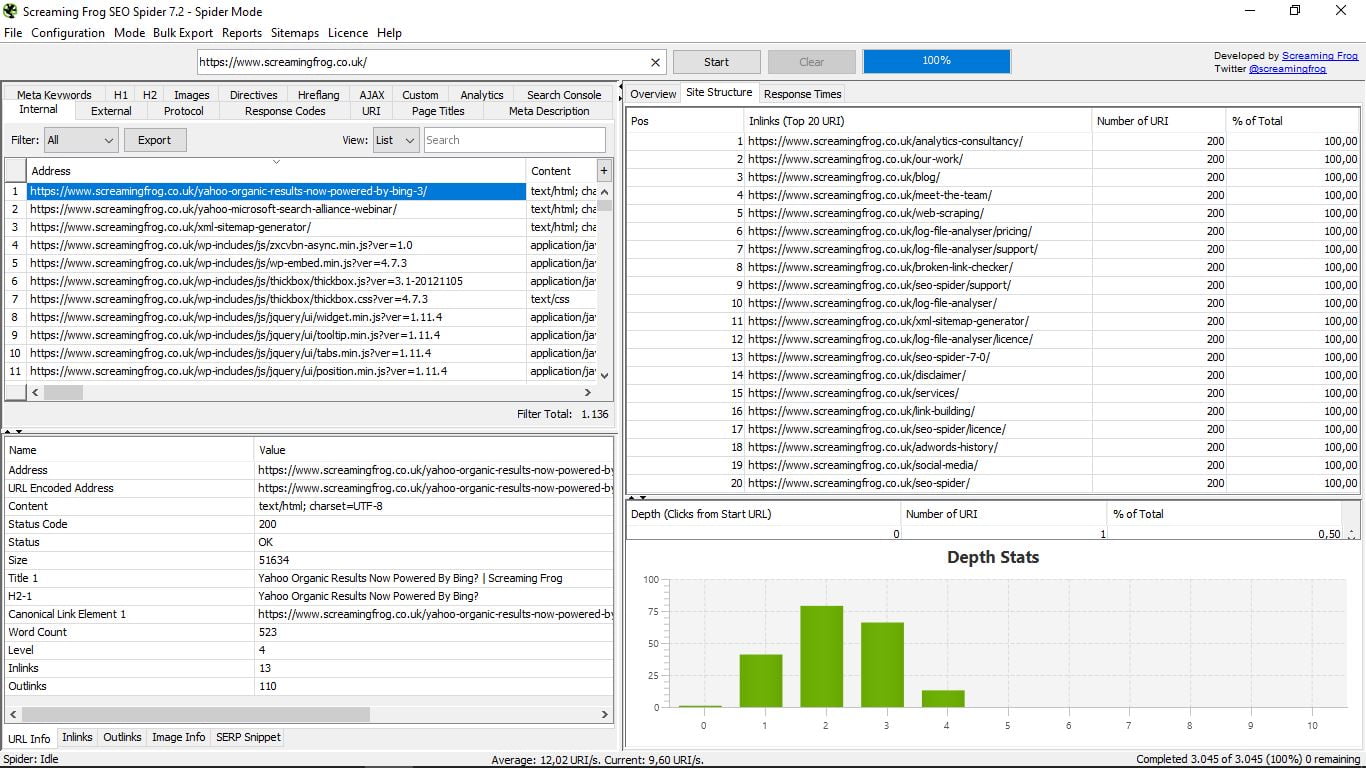
- Struktura witryny, z 20 najlepszymi adresami URL i statystyką głębokości, czyli odległością, z której każda strona znajduje się od głównego adresu URL lub domu, co zaleca się, aby nie przekraczało 3 kliknięć.
- Czasy odpowiedzi, które wskazują czasy ładowania każdej strony według zakresów. Musimy zawsze starać się być jak najmniejsi, ale jeśli spędzimy 4 sekundy, musimy to poprawić. Widzimy również średni czas ładowania całej sieci.
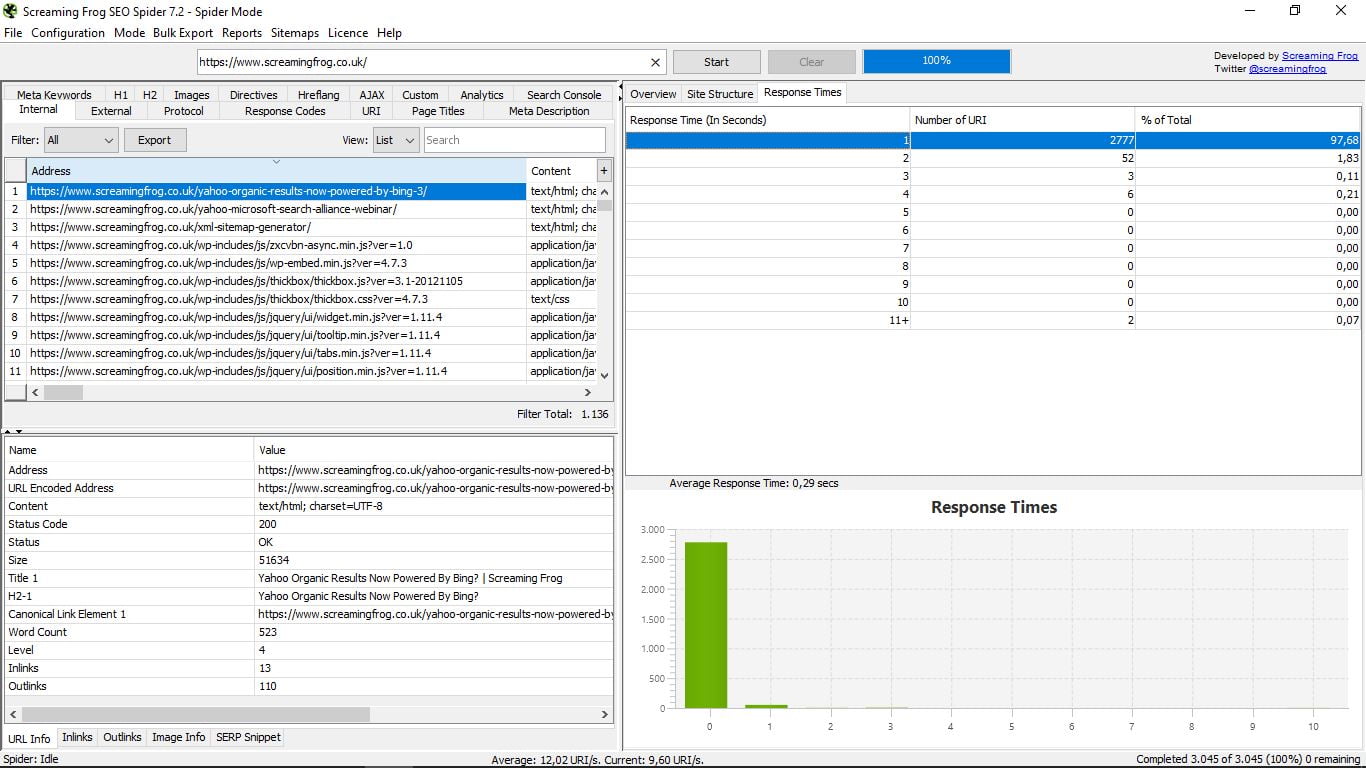
Te trzy cechy, jak widzieliście, są połączone na dole grafiką. Jest to jedyny element wizualny, który znajdujemy w Screaming Frog Seo Spider.
Cóż, gdy zobaczymy wszystkie możliwości oferowane przez Spidera, widzimy, że mamy do 17 sekcji, w których możemy zobaczyć konkretne dane ze wskazanej strony.
Do tej pory przyglądaliśmy się informacjom o wewnętrznych, wewnętrznych stronach, które są domyślnie zaznaczone. Ale po prostu kliknij dowolną inną opcję, aby zobaczyć, co nas interesuje.
3.1 Zewnętrzne
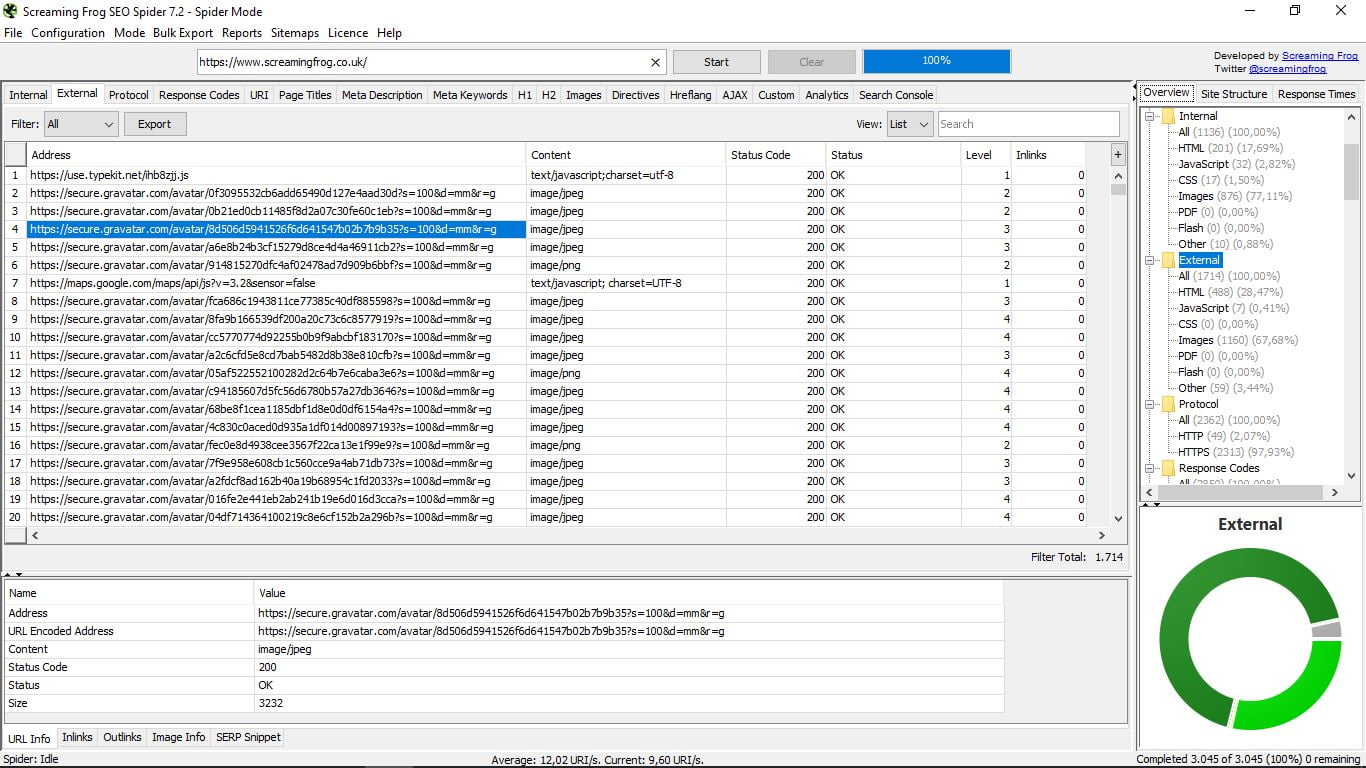
Wymienia zewnętrzne strony domeny naszego wyszukiwania, jego typ (jeśli jest to HTML, obraz, CSS, JavaScript, PDF, Flash, inne ...), jego kod statusu (200 Ok, 301, 404 ...), jego poziom i jego linki wewnętrzne
Pamiętaj, że po prawej stronie masz kolumnę z bardziej ogólnymi opcjami i jej grafiką, a pod wszystkimi pozostałymi pięcioma funkcjami, aby zobaczyć konkretne informacje o każdym adresie URL. Dotyczy to również wszystkiego, co zobaczymy.
3.2 Protokół
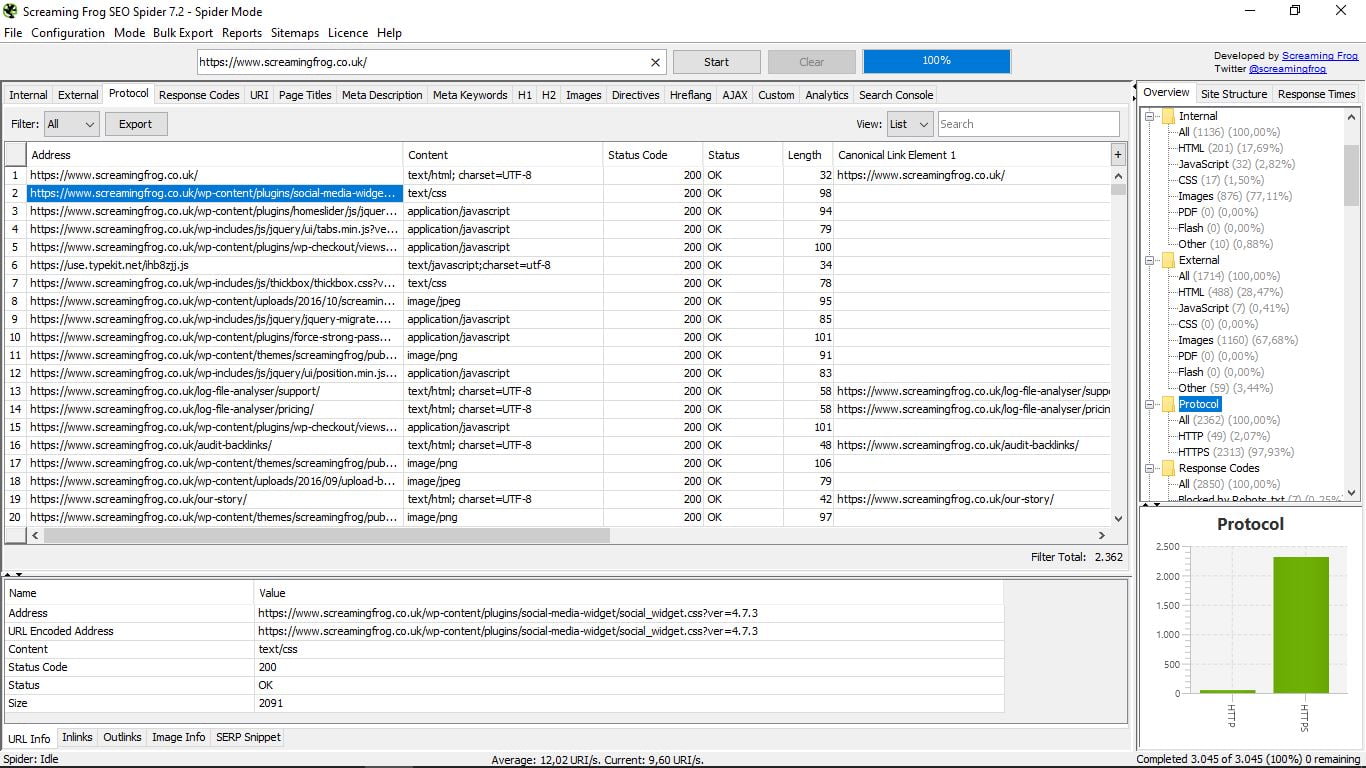
Strony zobaczymy zgodnie z ich protokołem bezpieczeństwa (http lub https), a także konkretnymi informacjami o każdym z nich (adres URL, typ formatu, status i kod statusu, długość, główne łącze kanoniczne).
3.3 Kody odpowiedzi
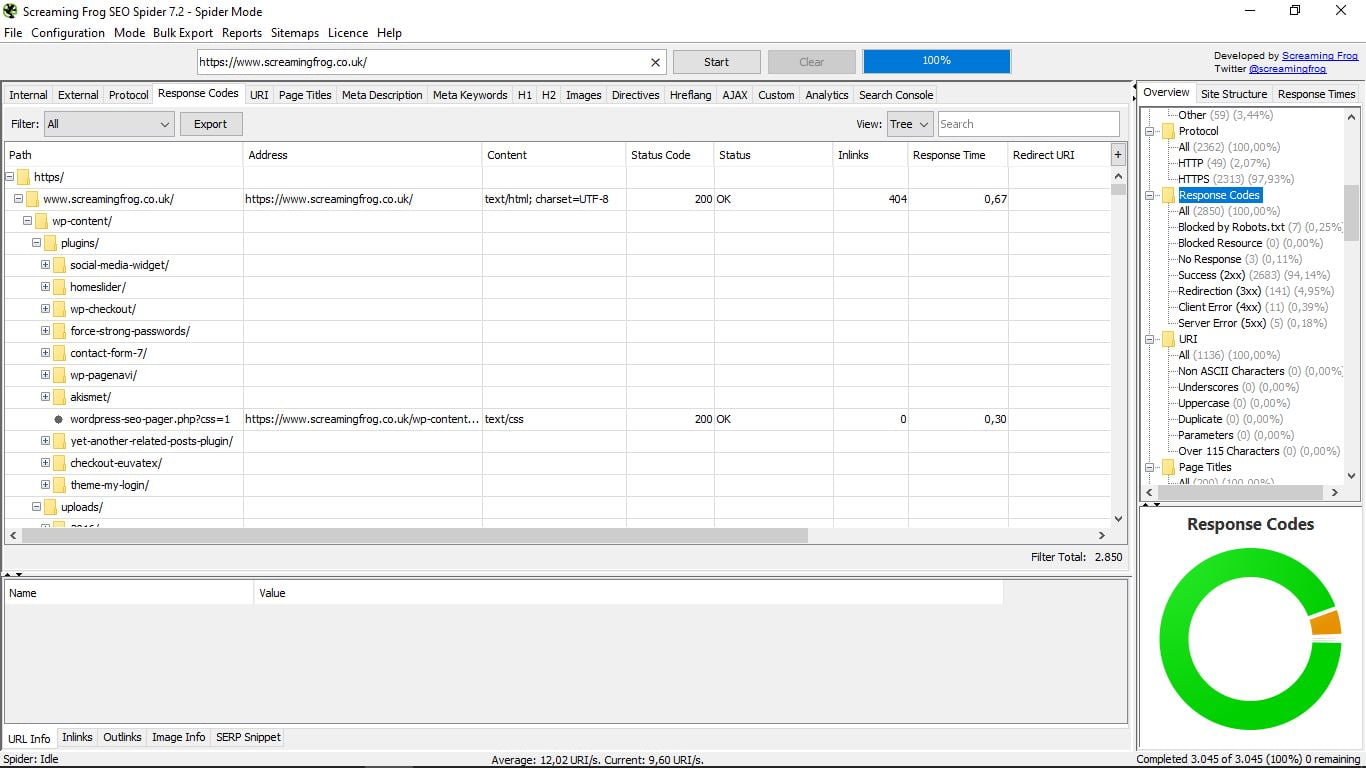
Aby zobaczyć kody odpowiedzi serwera, lepiej jest wybrać widok drzewa zamiast listy, która jest domyślnie wyświetlana. W ten sposób lepiej wykryjemy strony zablokowane przez plik Robots.txt, zablokowane zasoby, adresy URL, które nie odpowiadają, te, które to robią, przekierowane i te, które powodują błąd klienta i błąd serwera.
Poprawienie lub wyeliminowanie tych, które dają te błędy 4XX lub 5XX jest niezbędne, aby nasza strona była dobrze zoptymalizowana.
3.4 URI
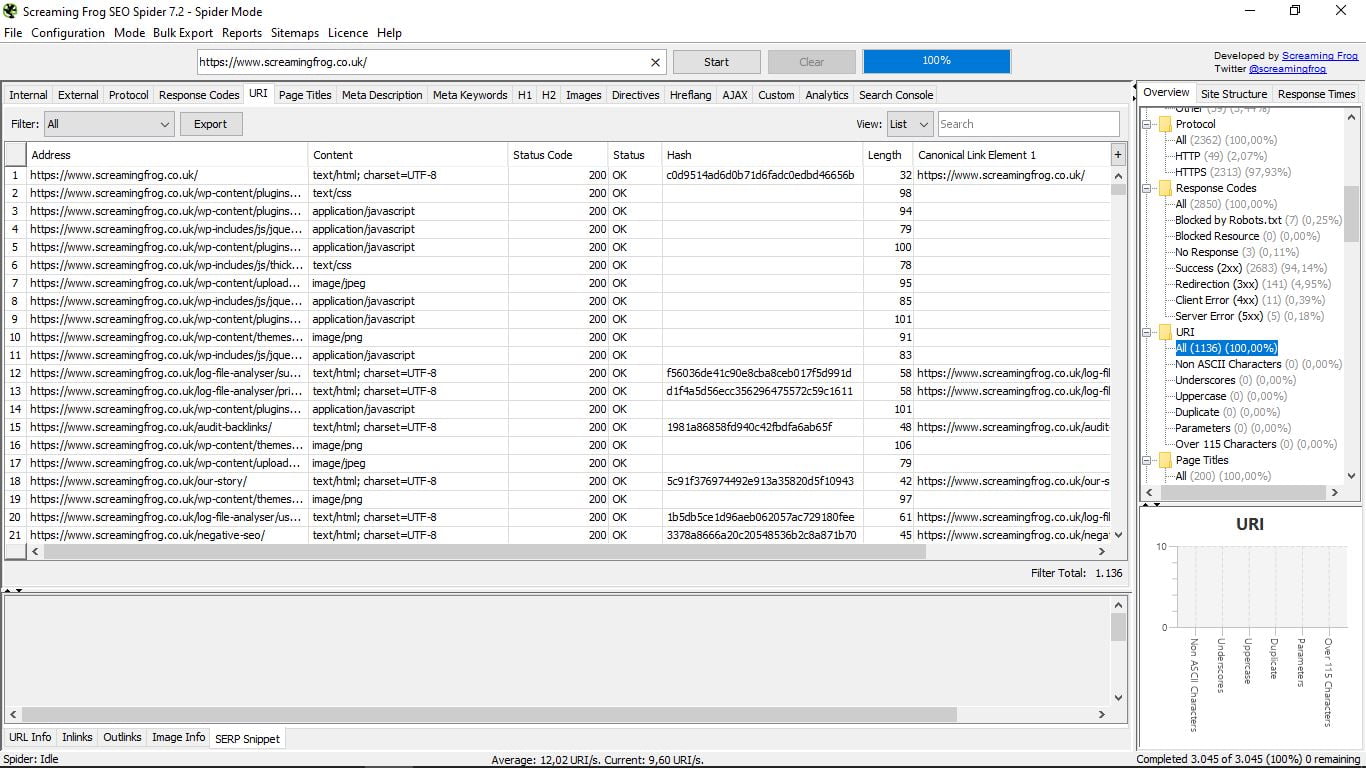
Sekcja techniczna, aby zobaczyć adresy według Uniform Resource Identifier (URI): bez znaków języka ASCII, podkreśleń, wielkich liter, duplikatów, parametrów i powyżej 115 znaków.
3.5 Tytuł strony
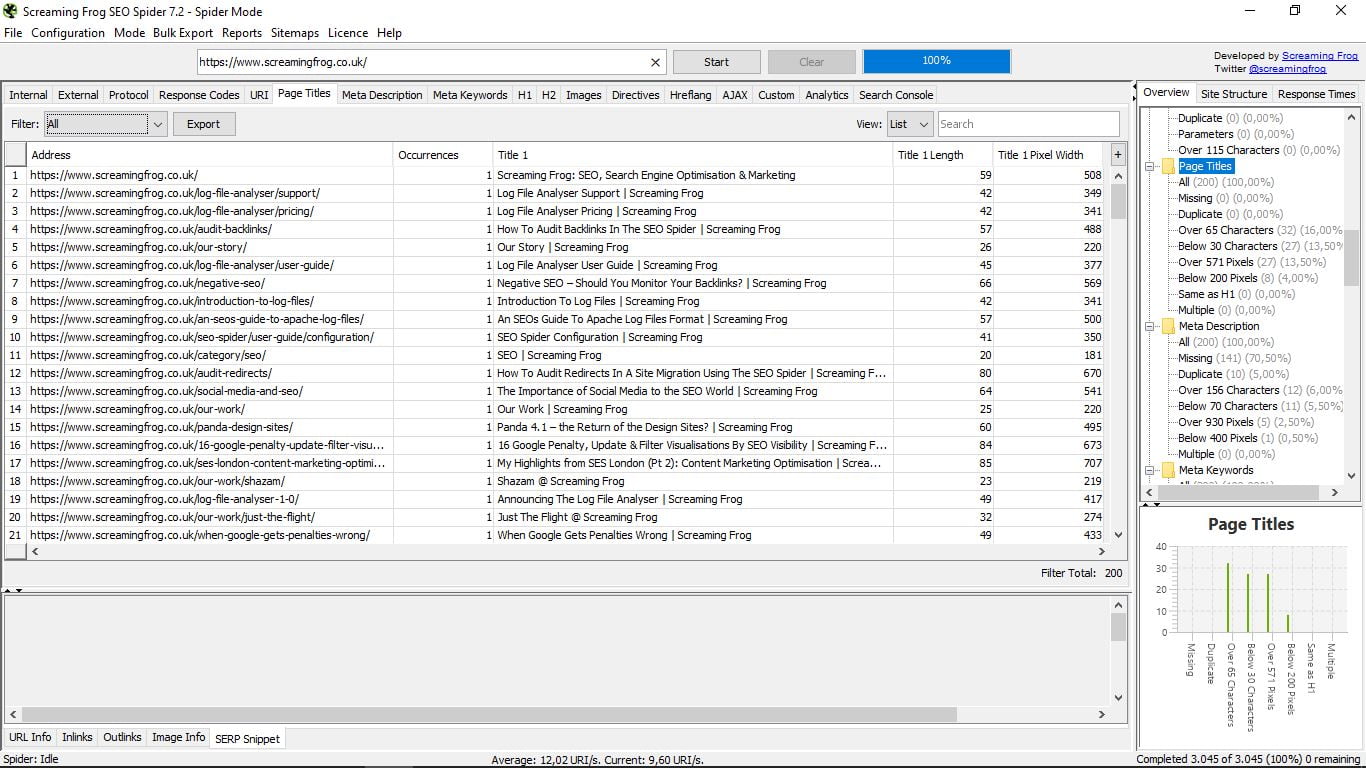
Miejsce, w którym będziemy mogli szybko zobaczyć wszystkie tytuły naszych stron, ich długość i szerokość w pikselach. Przydatne do wykrywania stron bez nich lub do duplikatów powyżej 65 znaków lub poniżej 30 (przystanki zalecane przez Google); powyżej 571 pikseli lub poniżej 200; tak samo jak H1; lub wiele.
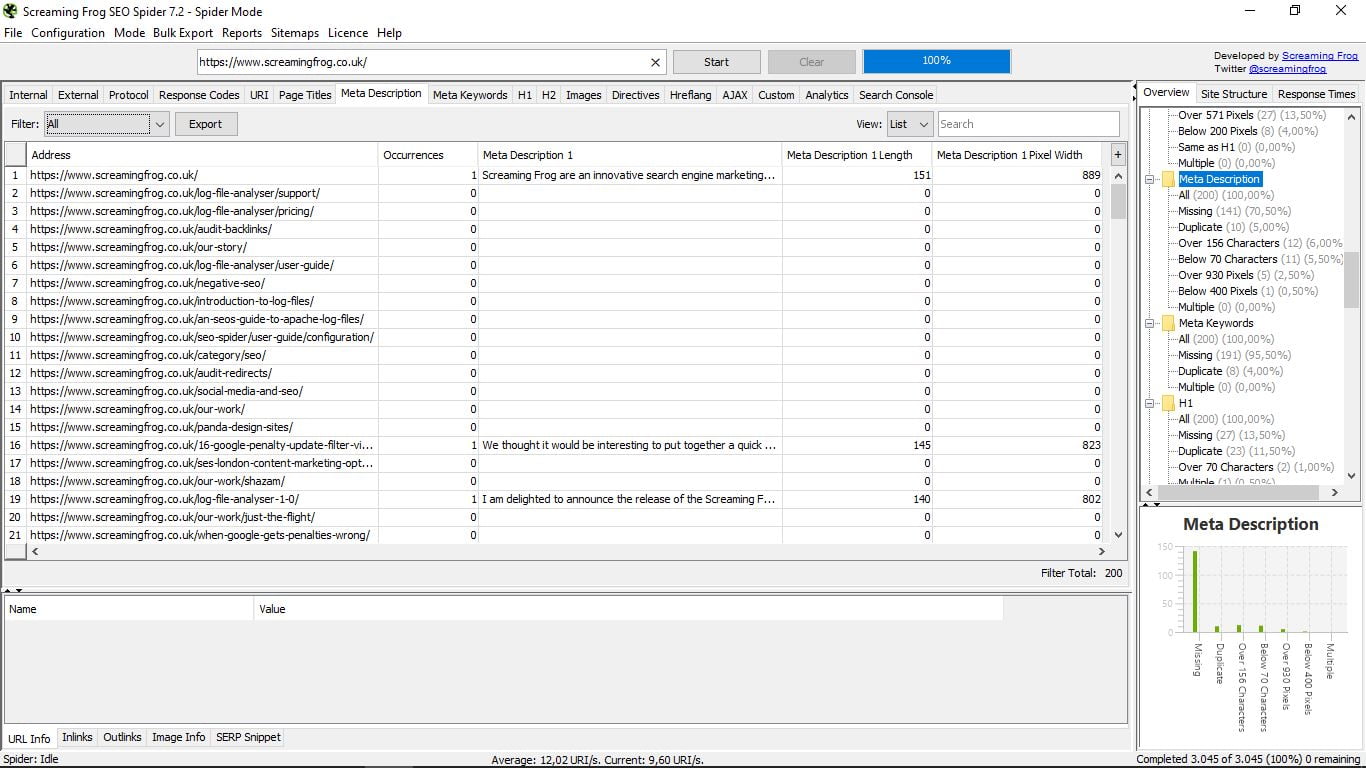
Tutaj zobaczymy meta opisy każdej z naszych stron, również z ich długością i szerokością w pikselach.
Podobnie jak w poprzedniej sekcji, pozwala nam zobaczyć, ile stron nie ma, ile ma duplikatów, powyżej 156 znaków lub poniżej 70; lub powyżej 930 pikseli i poniżej 400; i ile ma wielu.
Przypominamy jeszcze raz, że możesz filtrować za pomocą „Filtru”, który znajduje się po lewej stronie pola z listą adresów URL lub kolumną po prawej stronie.
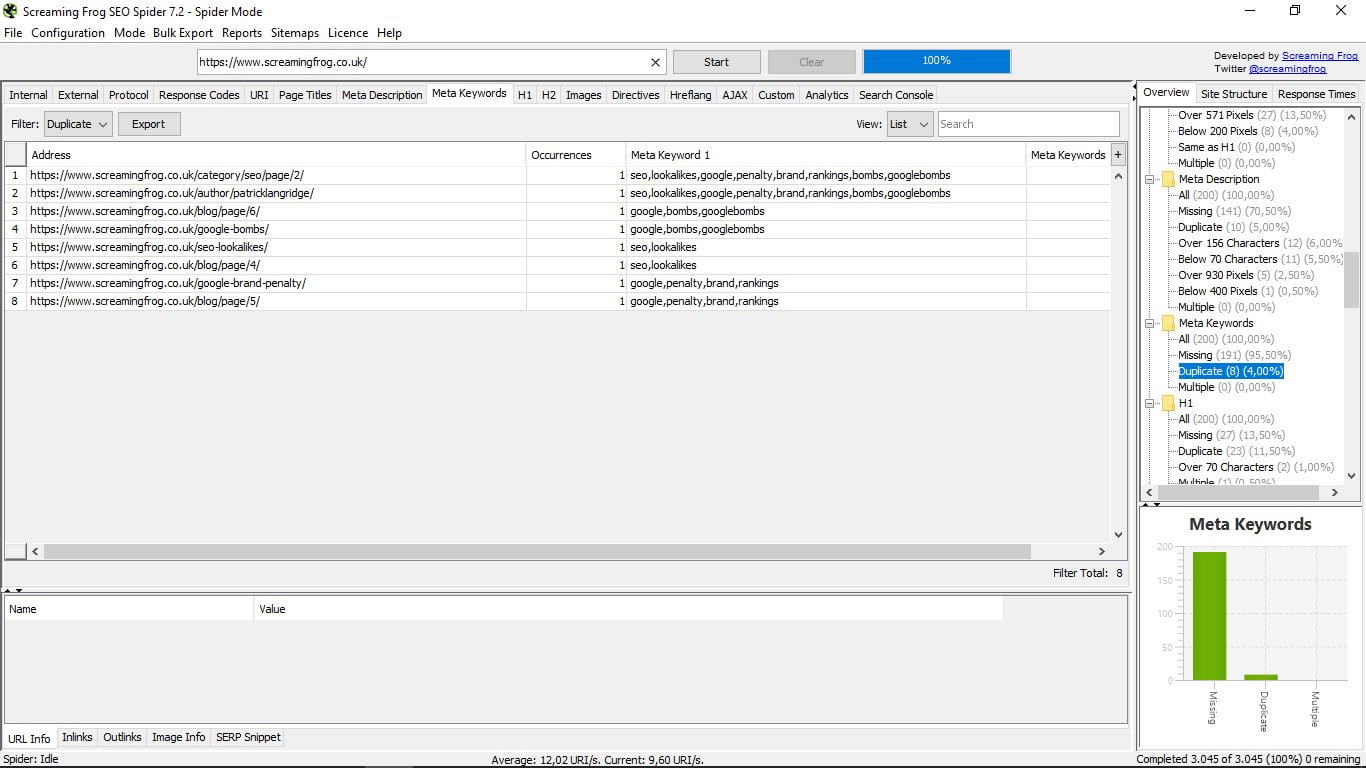
Ta funkcja jest prawdą, że jest przestarzała, ponieważ Google przestało brać pod uwagę meta słowa kluczowe, które prawie nikt ich nie używa. Ale jest, jeśli ktoś jest ciekawy, które strony i które używają (lub raczej używają) swoich kompetencji.
3.8 Etykieta H1
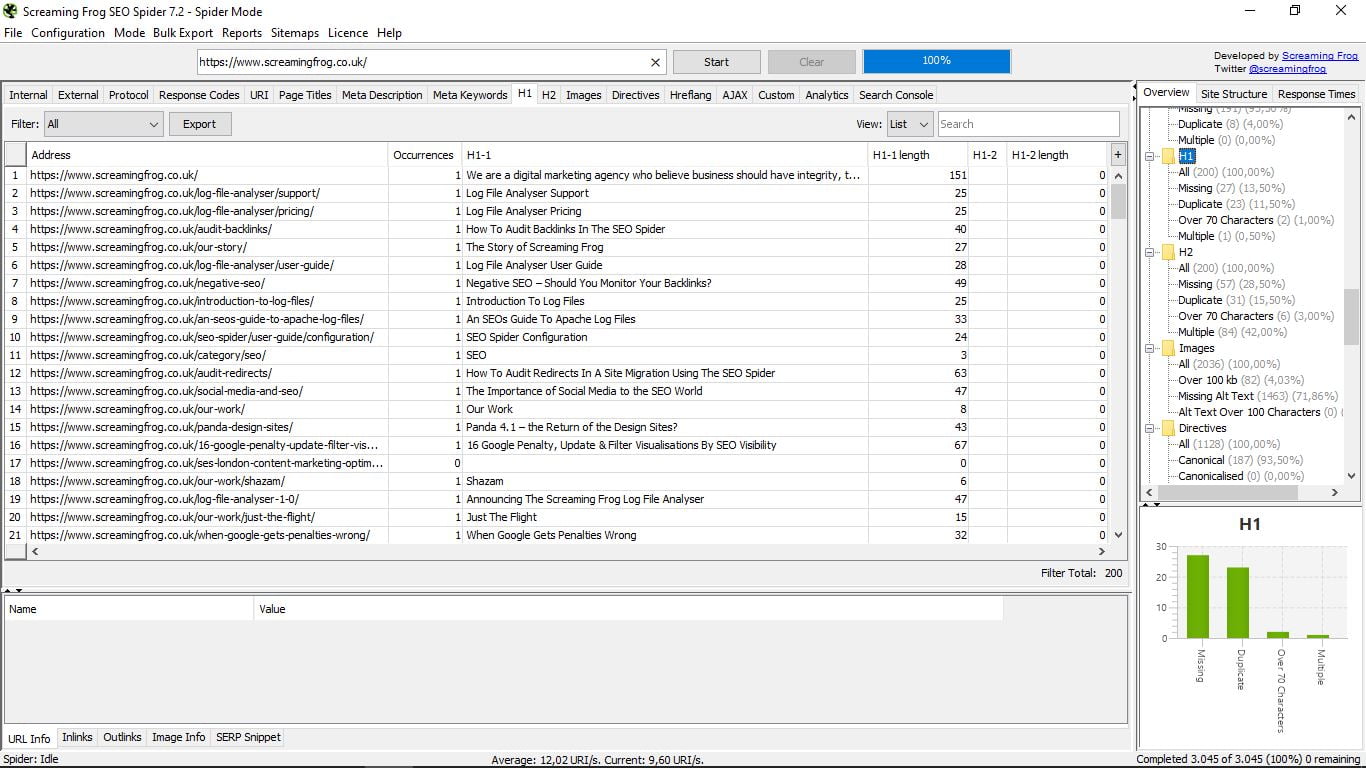
Przeszliśmy od sekcji bez użyteczności do sekcji o dużym znaczeniu. Tutaj pokazujemy H1 każdej z naszych stron (lub konkursu, zgodnie ze stroną internetową, z której przeprowadziliśmy wyszukiwanie).
Wskazuje długość znaków i jeśli jest więcej niż jedna dla tej samej strony (niezalecane). W kolumnie po prawej stronie możemy z prostym spojrzeniem wiedzieć, ile stron nie ma H1, ile jest duplikatów, które przekraczają 70 znaków i wiele przypadków.
3.9 Etykiety H2
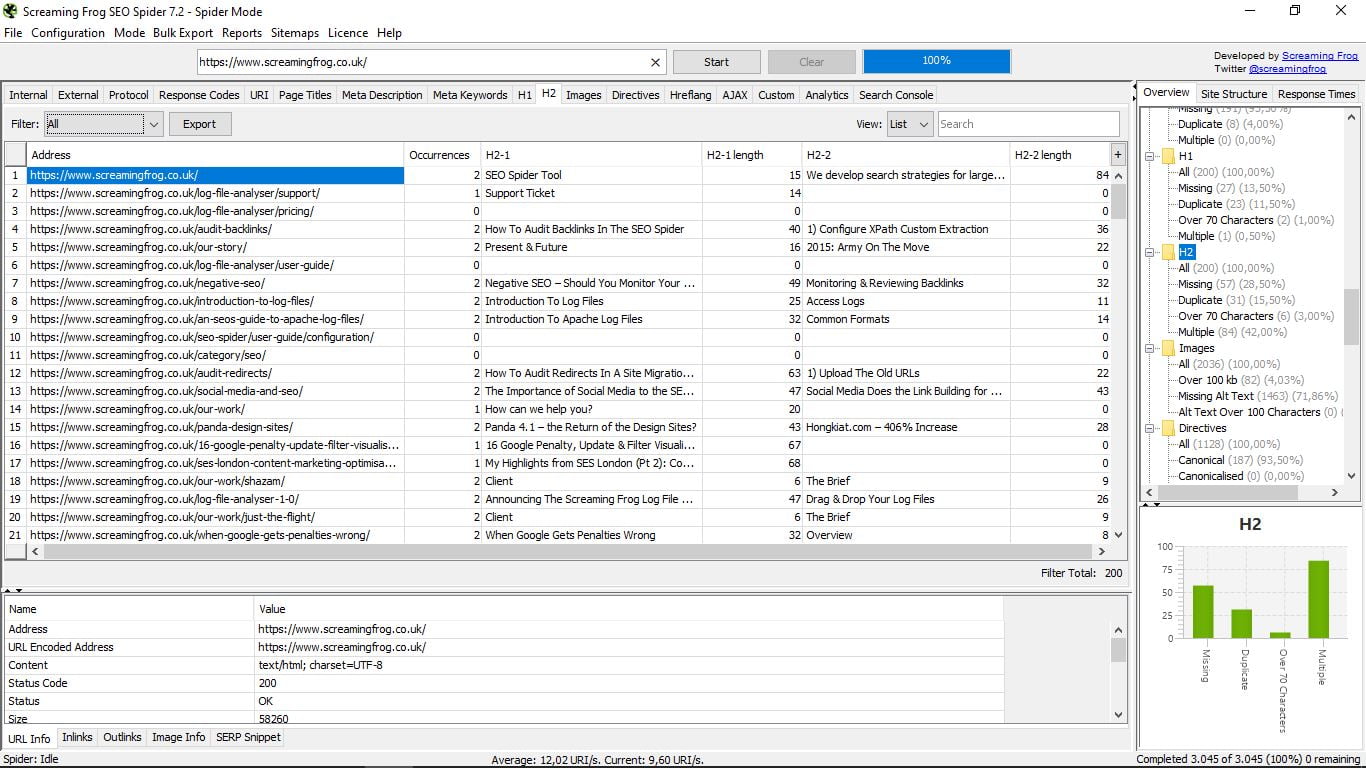
Dokładnie taki sam jak poprzedni, ale teraz dla H2, gdzie zasadnicza różnica polega na tym, że H2 może mieć więcej niż jeden bez problemu. Tutaj dwie pierwsze są pokazane dla każdej strony.
3.10 Obrazy
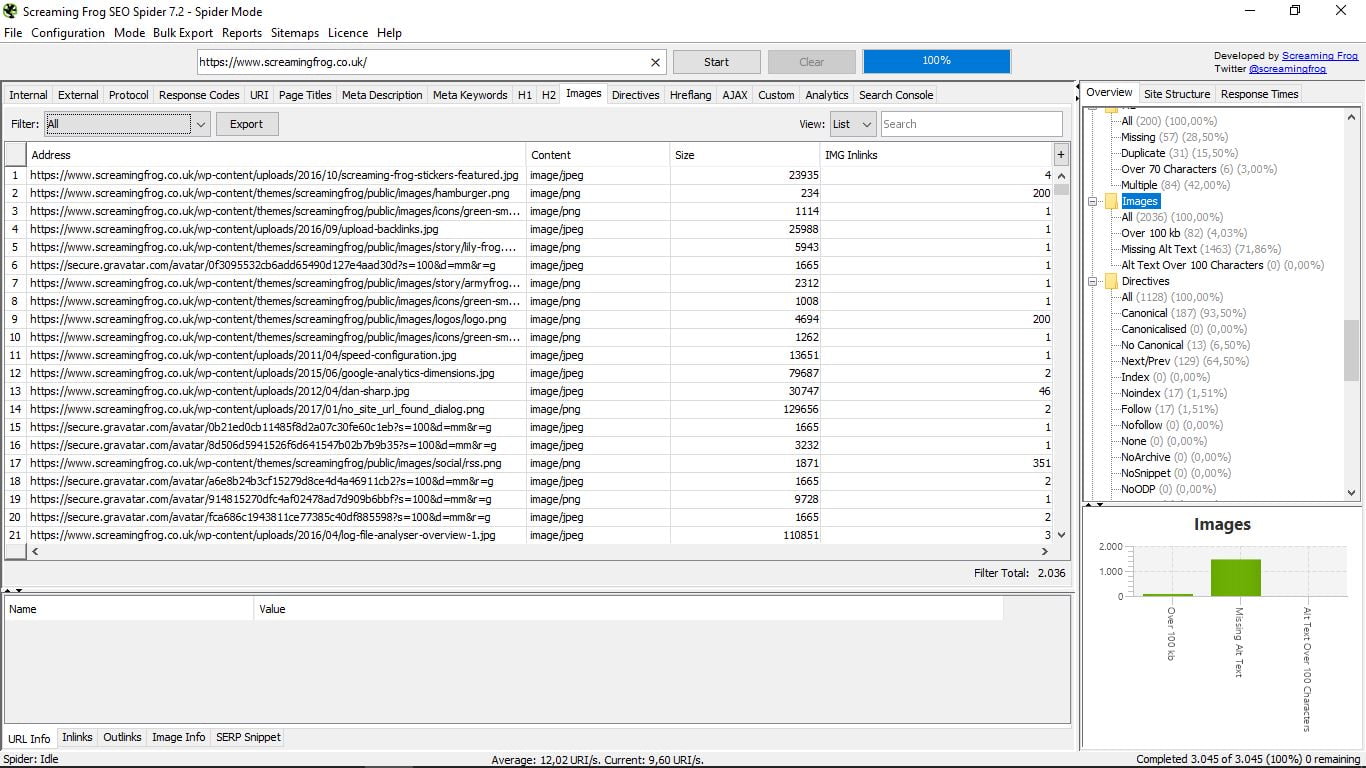
Radiogramuje wszystkie obrazy sieci, wskazując jej adres, jej format (PNG, JPEG ...), jego wagę w Kb oraz wewnętrzne linki. Po prawej lub w filtrach możemy znaleźć te, które ważą więcej niż 100 kb, te, które nie mają Alt Text lub te, w których przekracza 100 znaków.
3.11 Dyrektywy
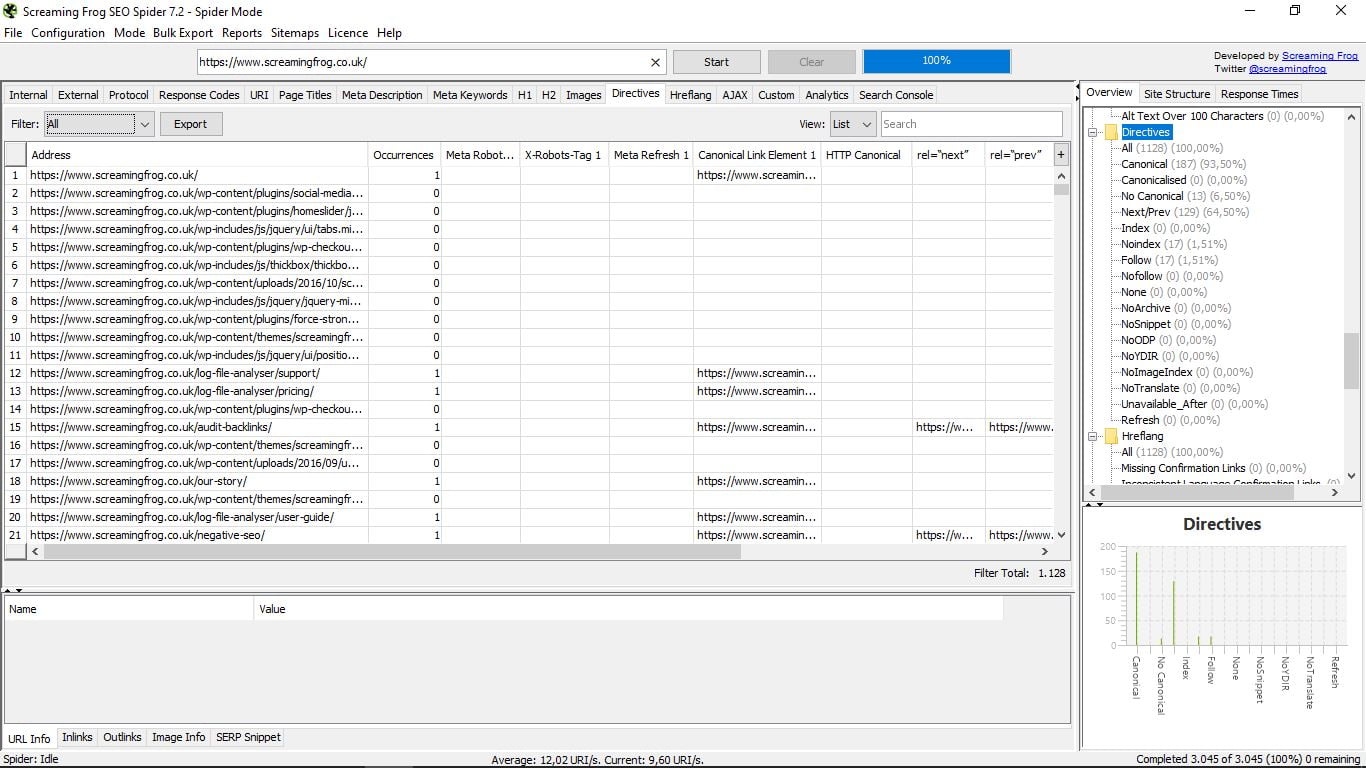
Znajdziemy tutaj dyrektywy, które regulują każdą stronę (kanoniczna, następna-prev, indeks / brak indeksu, follow / nofollow, nie tłumacz ...). Możesz przejrzeć długą listę po prawej stronie, z ich odpowiednimi wartościami procentowymi i wykresem, lub bezpośrednio w polu listy wyników.
3.12 Etykiety Hreflang
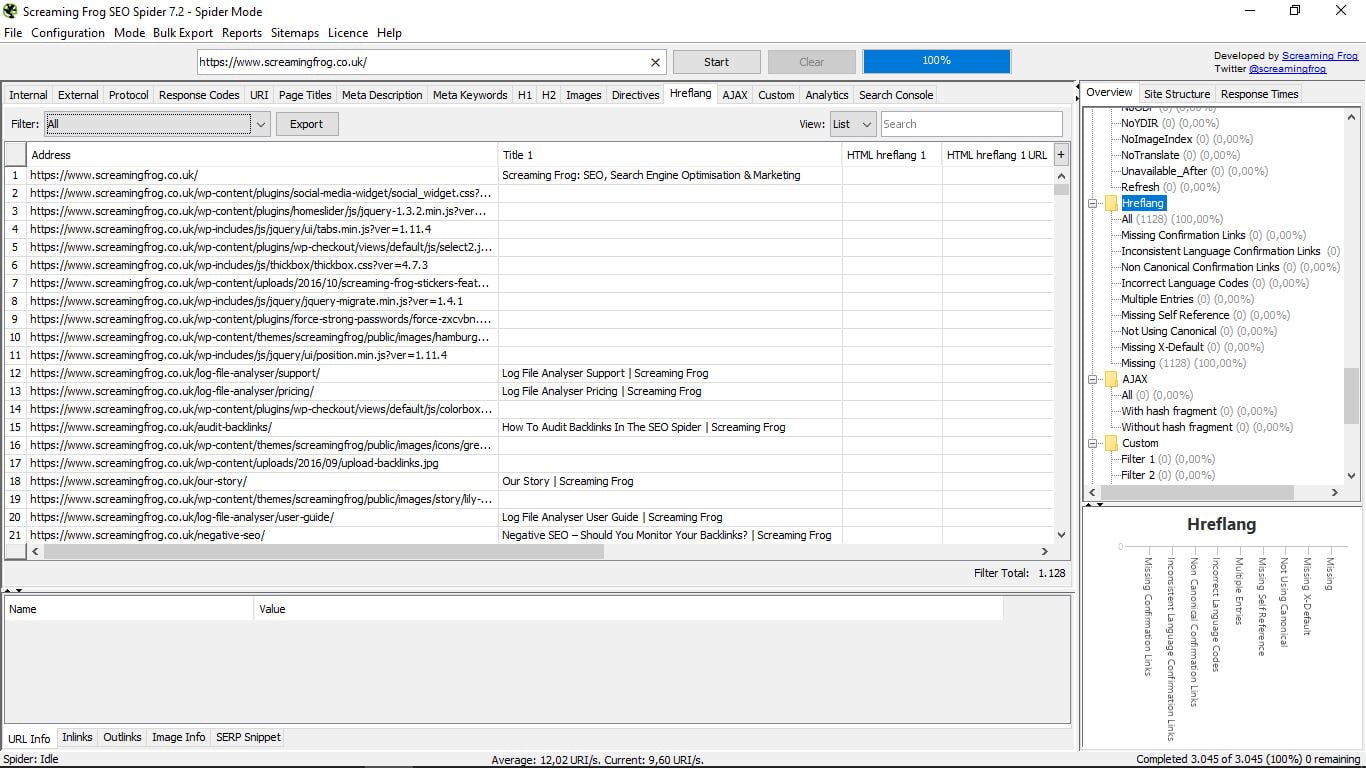
Jeśli zaznaczyłeś swoją stronę jako wielojęzyczną w Google Search Console, będziesz miał tagi Hreflang. Ta sekcja określa je i ostrzega przed możliwymi błędami. Często zdarza się, że implementacja tych tagów kończy się niepowodzeniem.
Tutaj łatwo zobaczysz, co nie powiedzie się w każdym przypadku: jeśli nie jest odwrotne, jeśli nie ma kanonicznego lub X-default, itp.
3.13 AJAX
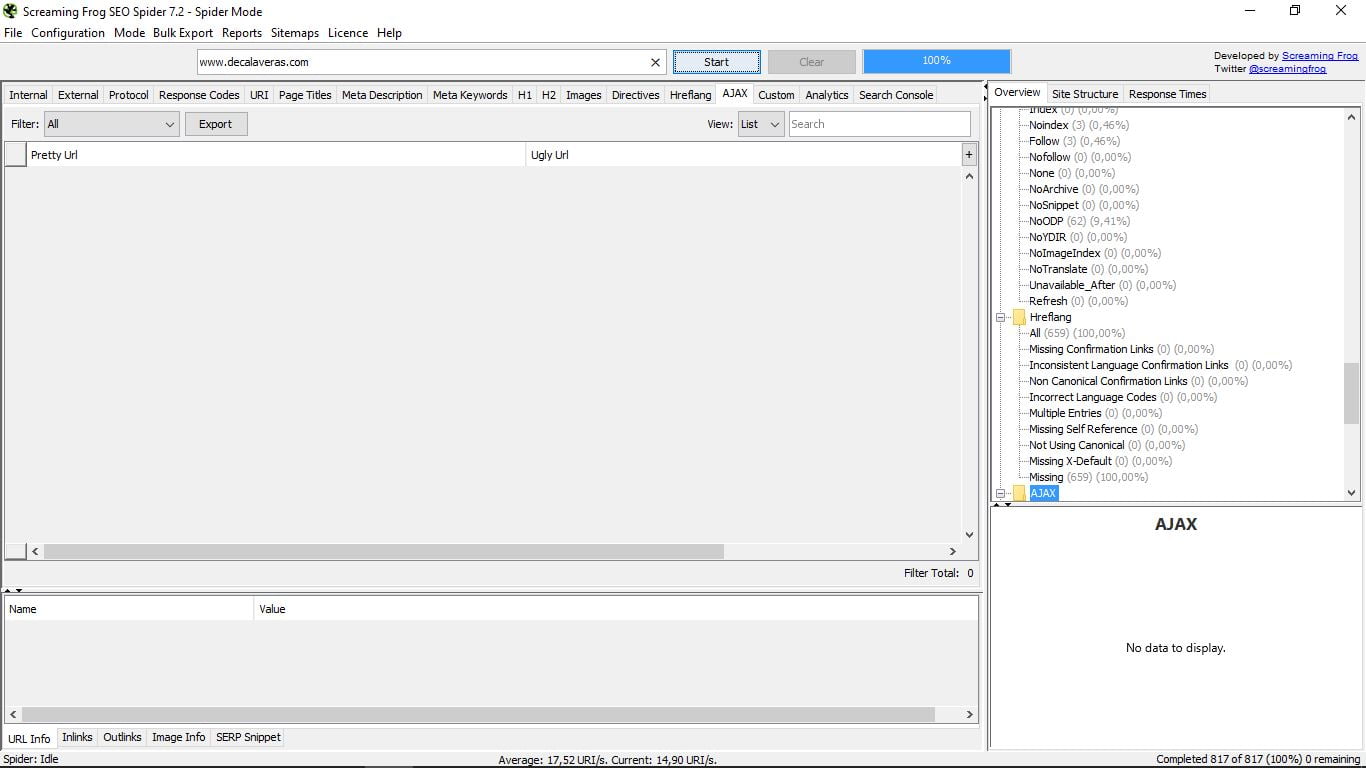
Nie ma nic wspólnego z detergentem ani z drużyną piłkarską w Amsterdamie; _) Są to skróty Asynchronous JavaScript And XML (asynchroniczny JavaScript i XML) i jest to technika tworzenia stron internetowych używana do tworzenia interaktywnych aplikacji.
Zazwyczaj, jeśli Twoja witryna jest „normalna”, ta sekcja jest pusta, jak w przypadku przykładu.
3.14 Niestandardowe
Jest to sekcja umożliwiająca wyszukiwanie za pomocą niestandardowych filtrów. W tym celu musisz je wcześniej skonfigurować. Odbywa się to w menu głównym „Konfiguracja” i wewnątrz niego w „Niestandardowe”:
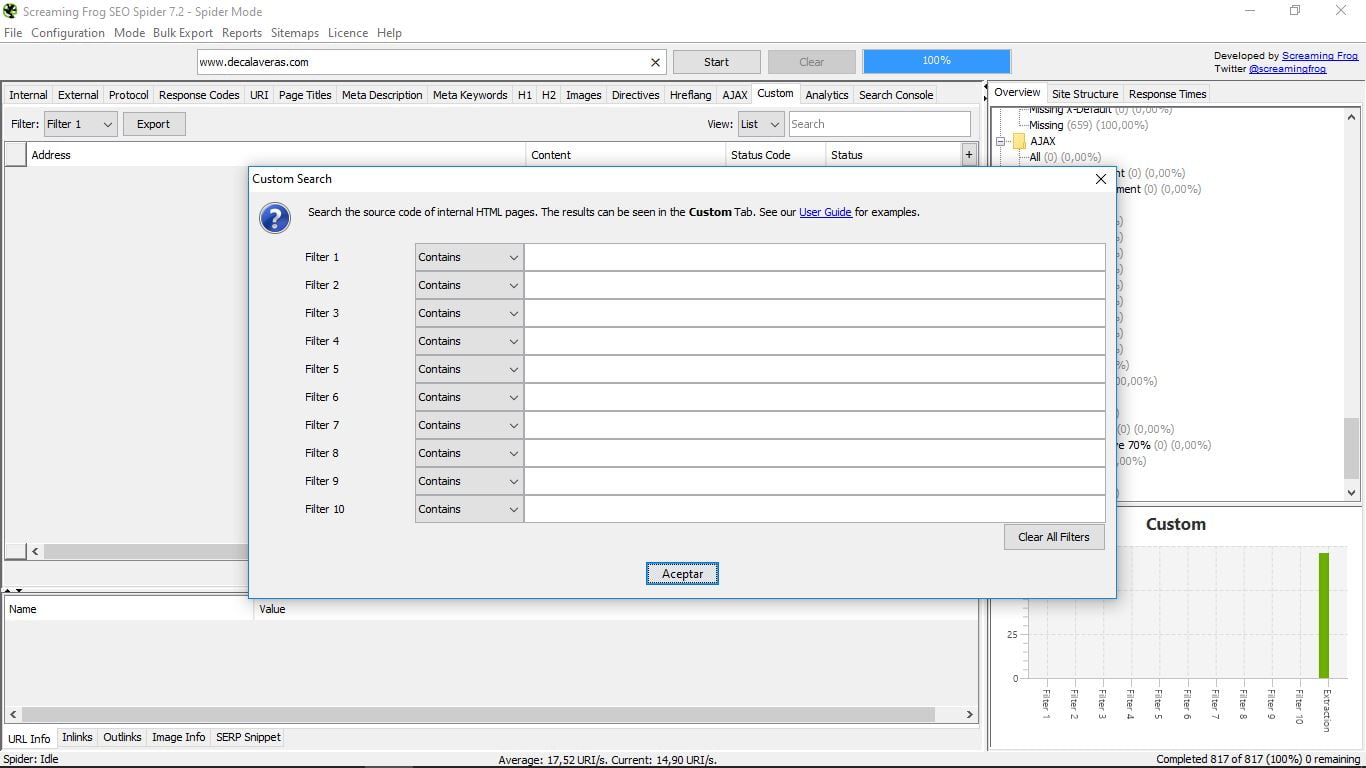
Tam mamy opcję „Szukaj”, czyli wyszukiwanie lub „Ekstrakcja”, aby uzyskać pewne elementy naszych wewnętrznych stron HTML. W obu przypadkach musimy wybrać żądane parametry i zapisać je, a następnie wykonać wyszukiwanie z „Niestandardowe”.
3.15 Analytics
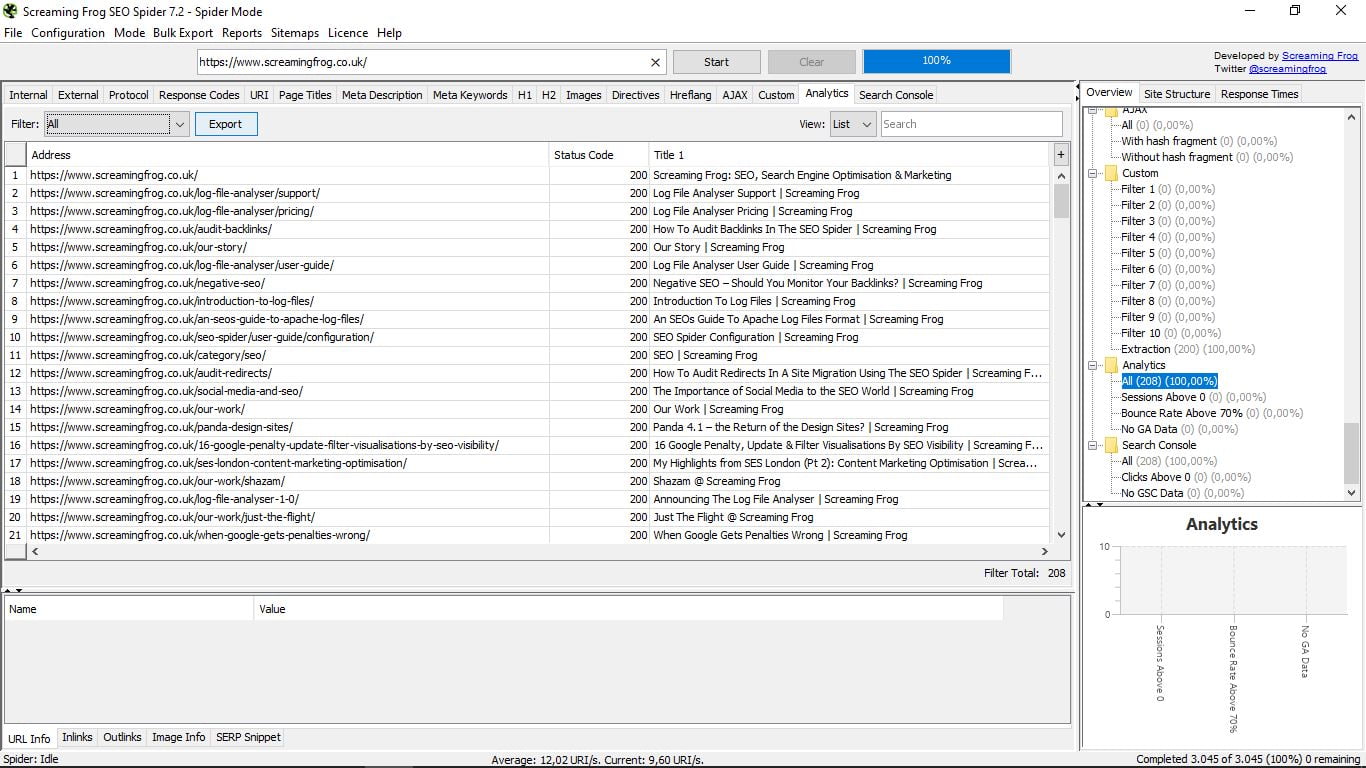
Podczas łączenia narzędzia z Google Analytics możemy zobaczyć poprzednie sesje, współczynniki odrzuceń powyżej 70% lub brak danych Analytics.
3.16 Konsola wyszukiwania
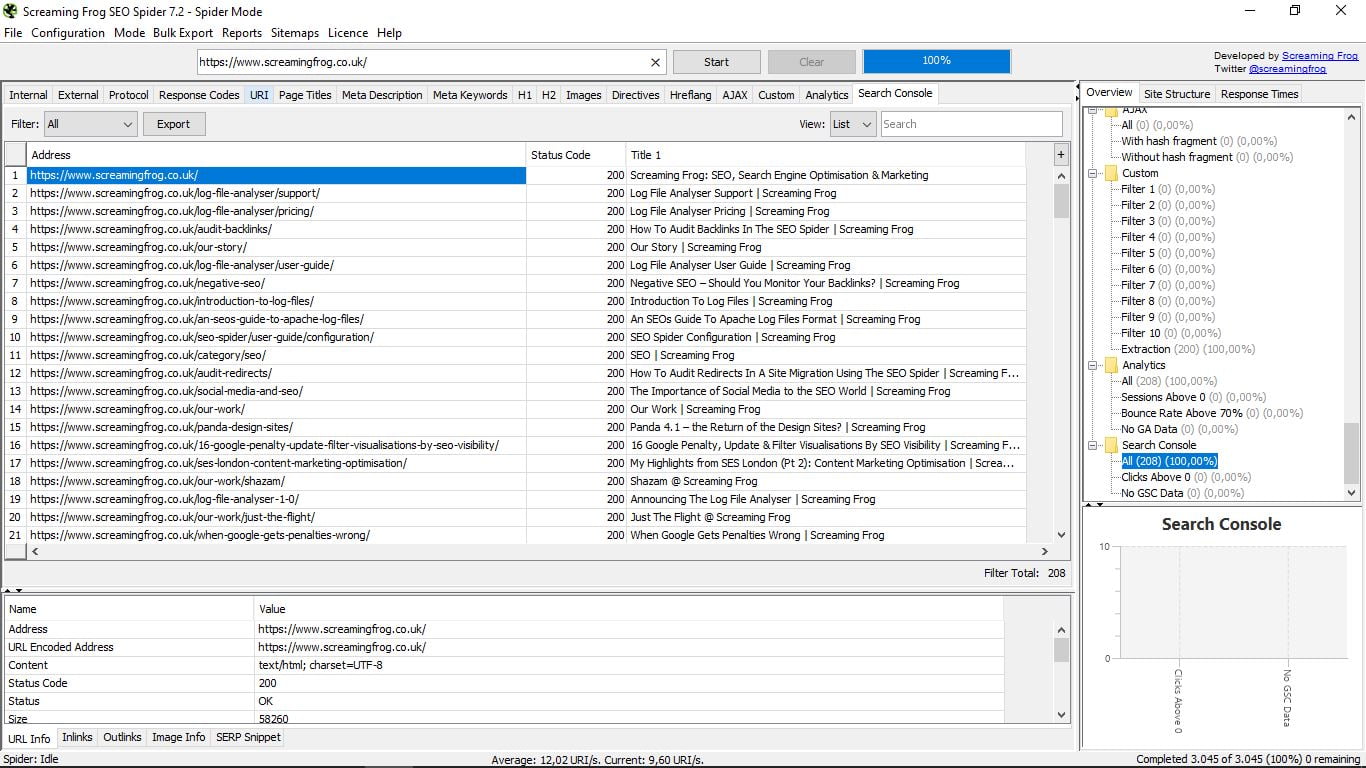
Tak samo jak w poprzednim, ale w tym przypadku dla narzędzia Google Search Console.
4. Tryb listy
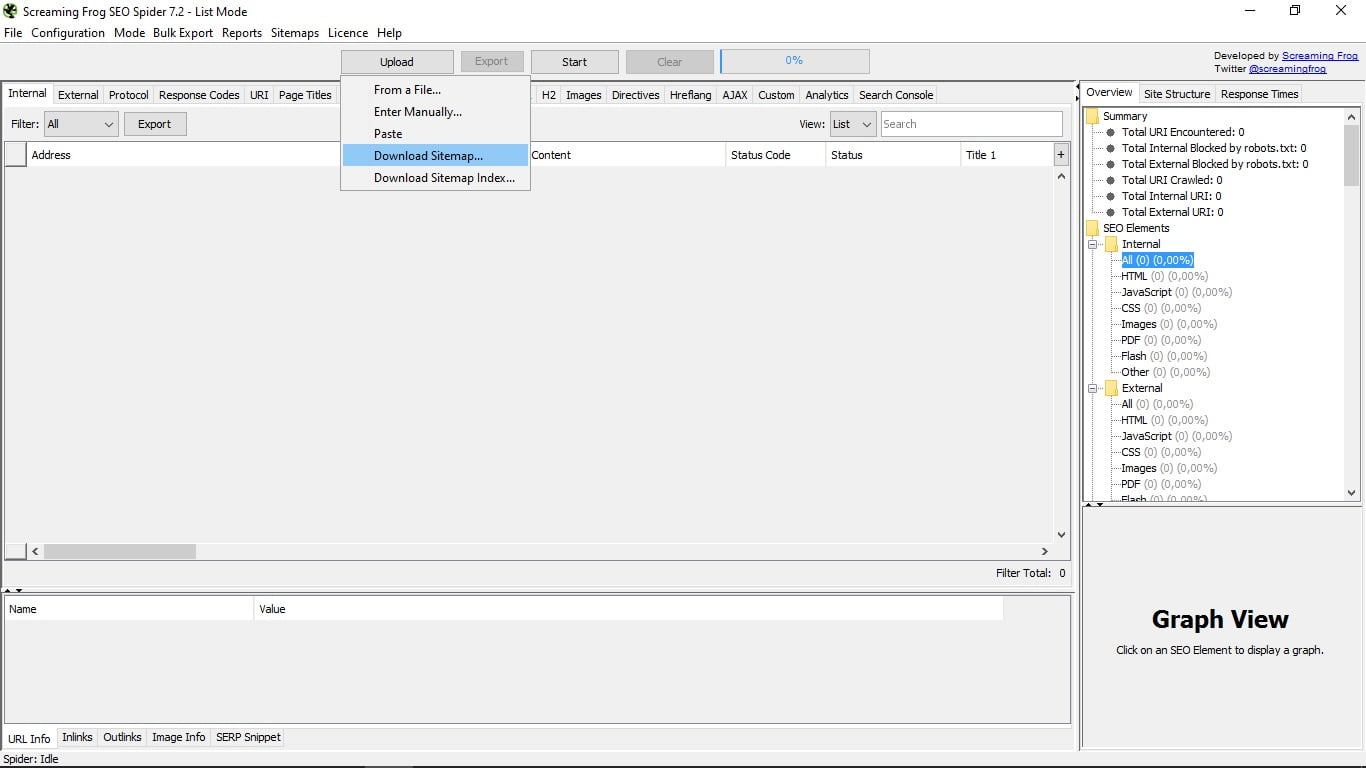
Tutaj narzędzie pozwala nam załadować listę adresów URL, które zgromadziliśmy w dokumencie. Istnieje również możliwość ręcznego wprowadzania ich, wklejania ich lub pobierania z mapy witryny lub indeksu mapy witryny adresu URL, który Ci przekazujemy.
Stamtąd funkcje narzędzia są dokładnie takie same jak w trybie pająka.
5. Tryb SERP
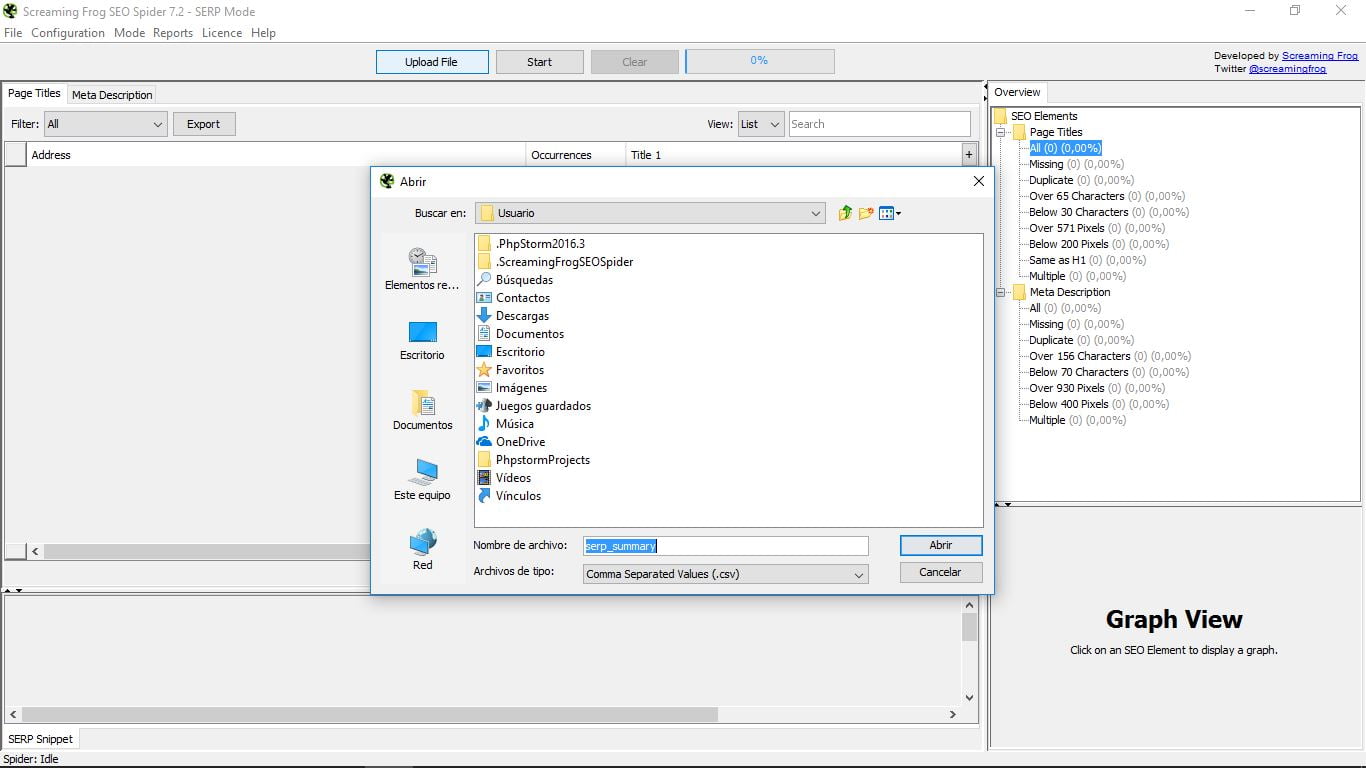
Ta trzecia opcja wymaga również obciążenia z naszej strony, w tym przypadku dokumentu CSV z adresami URL, które chcemy analizować. Zobaczymy ich tytuł i opisy meta. Pozostałe funkcje są dokładnie takie same jak w poprzednich dwóch trybach.
6. Dodatkowy utwór
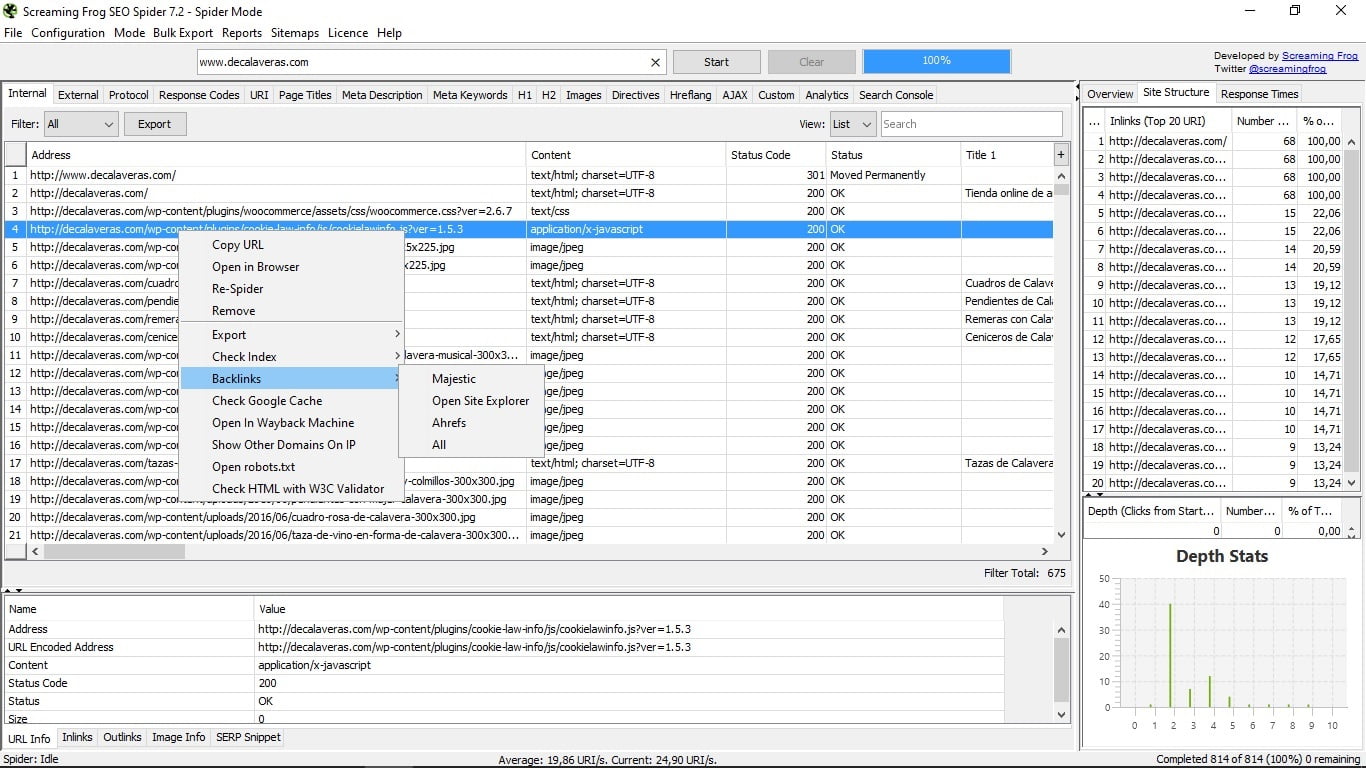
Mała sztuczka pudełkowa, w której nie wszyscy spadają. Jeśli klikniesz prawym przyciskiem w dowolnym URL, będziesz miał bardzo przydatne menu, gdzie pozwoli ci:
- Skopiuj adres URL
- Otwórz go w przeglądarce.
- Spraw, by pająk ponownie go śledził.
- Usuń go z listy.
- Wyeksportuj informacje o tym adresie URL, jego linki wewnętrzne, linki zewnętrzne, dane obrazów i rejestrację ścieżki śledzenia.
- Sprawdź ich indeksowanie w Google, Yahoo, Bing lub wszystkie naraz.
- Zobacz linki zwrotne tego adresu URL za pośrednictwem narzędzi Majestic Seo, Open Site Explorer i Ahrefs.
- Zobacz pamięć podręczną tej strony w Google.
- Otwórz go na Wayback Machine, stronie internetowej, która pokazuje, jak strona była w archiwalnych rekordach, które zarchiwizowałeś.
- Pokaż inne domeny, które są na tym samym IP co ta strona.
- Otwórz plik robots.txt, który zarządza tą stroną.
- Sprawdź możliwe błędy HTML na stronie dzięki walidacji narzędzia W3C.
7. Inne narzędzia Screaming Frog
Screaming Frog oferuje teraz także inne narzędzia, takie jak Analizator plików dziennika , analizator dziennika. Narzędzie to umożliwia przesyłanie plików rejestru, identyfikowanie przeszukiwanych adresów URL i analizowanie zachowania pająka, dzięki czemu jest bardzo przydatne dla SEO.
Ma darmową wersję i możesz kupić licencję, aby cieszyć się wszystkimi dodatkowymi funkcjami. Ale to narzędzie i zobaczymy je szczegółowo w innym ekskluzywnym samouczku.
Powiedz mi, czy masz jakieś pytania na temat Screaming Frog Seo Spider? Czy to narzędzie, którego używasz?
Powiedz mi, czy masz jakieś pytania na temat Screaming Frog Seo Spider?Czy to narzędzie, którego używasz?