 Товаров:
Товаров:
- 1. Як встановити Screaming Frog
- 100% безкоштовний курс SEO.
- 3. Режим Павука
- 3.1 Зовнішній
- 3.2 Протокол
- 3.3 Коди відповідей
- 3.4 URI
- 3.5 Назва сторінки
- 3.8 Етикетка H1
- 3.9 Мітки Н2
- 3.10 Зображення
- 3.11 Директиви
- 3.12 Етикетки Hreflang
- 3.13 AJAX
- 3.14 Користувальницькі
- 3.15 Аналітика
- 3.16 Консоль пошуку
- 4. Режим списку
- 5. Режим SERP
- 6. Бонусний трек
- 7. Інші інструменти Screaming Frog
Ви хочете дізнатися, як оптимізувати SEO на сторінці вашого сайту, як професіонала? Screaming Frog Seo Spider - найкращий інструмент у світі для аналізу сторінок URL-адреси веб-сторінок , Це скрепер, павук, який перевіряє павутину зверху донизу, посилаючись за посиланням, і аналізує його, показуючи вам все, що ви хочете знати про кожну з сторінок.
Вона розповідає, скільки текстових символів має кожна сторінка, її внутрішні та зовнішні посилання, метадані ... Вона вивчає все, тому вона ідеально підходить для виправлення помилок, поліпшення архітектури вашого сайту і, таким чином, поліпшення органічного позиціонування.
У цьому керівництві Screaming Frog я пояснюю крок за кроком, як працює інструмент і все, що ви можете проаналізувати.
1. Як встановити Screaming Frog
Screaming Frog є важливим інструментом і, на відміну від інших, це настільна програма, а не онлайн, тому вам доведеться завантажити його на свій комп'ютер з Секція SEO павука з головного меню веб-сайту, щоб використовувати його.
Вона має безкоштовну версію, за допомогою якої можна проаналізувати до 500 URL-адрес, але для збереження проектів і доступу до всіх його функцій необхідно придбати щорічну ліцензію, яка коштує 149 фунтів за поточним курсом обміну 172 євро. Вони менше 15 євро на місяць, і це того варте.
100% безкоштовний курс SEO.
- Створіть SEO оптимізований сайт
- Збільшіть трафік за допомогою безпечних стратегій
- Заробляйте з нею пасивні гроші
Після того, як ми вирішимо, яку версію ми будемо використовувати, ми перейдемо до завантаження.
Для цього підручника Streaming Frog версія інструменту становить 7.2. Можливо, вам буде запропоновано оновити JavaScript на комп'ютері, щоб його можна було запустити.
Добре, коли ми відкрили його, ми знайшли його основний інтерфейс, який, як ви бачите, досить строгий, насправді.
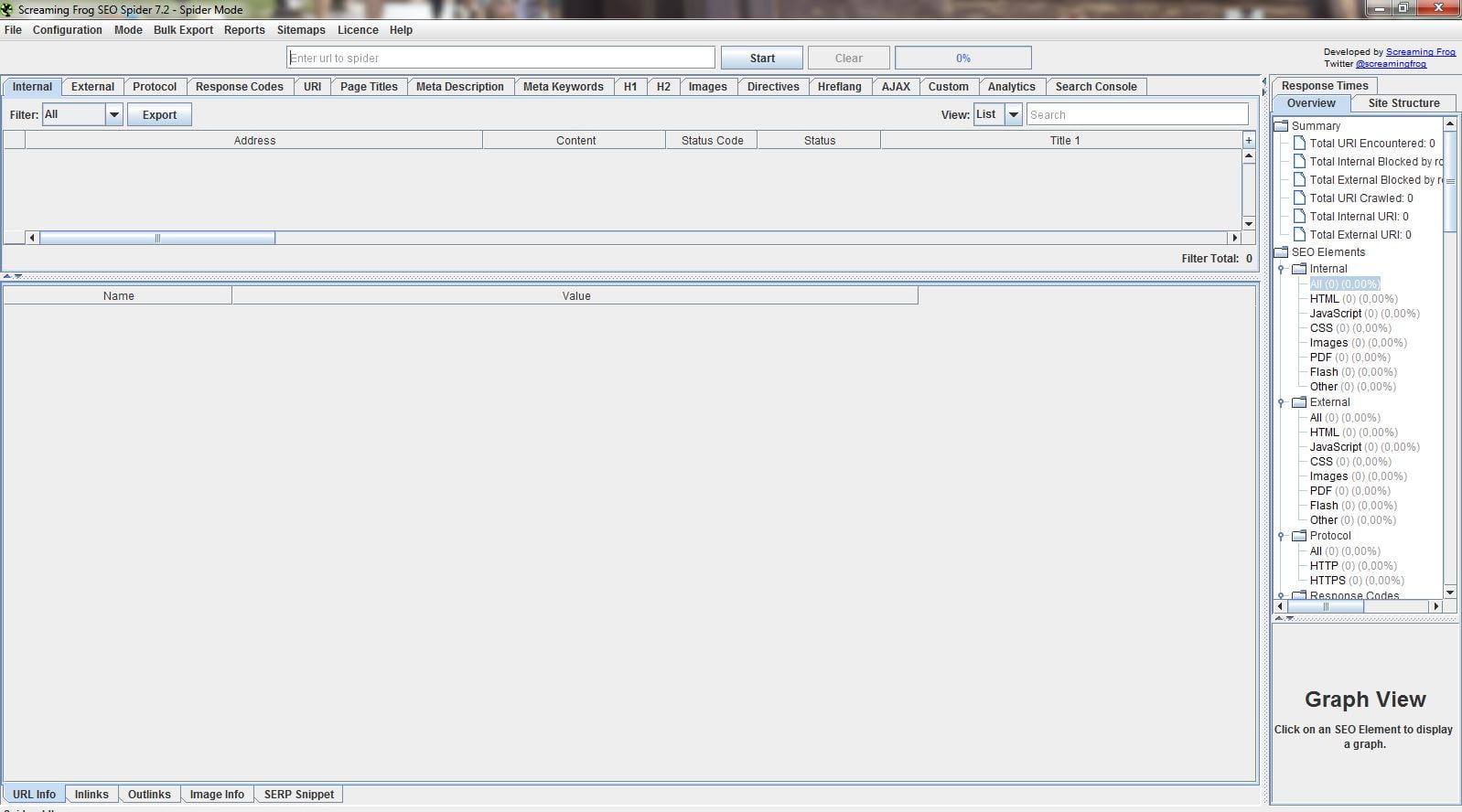
Давайте почнемо, розглядаючи те, що пропонує головне меню в тому, як він з'являється за замовчуванням, а це - Павук, що павук.
У меню "Файл" можна відкривати файли з будь-якого місця, відкривати нові і зберігати їх. Ми можемо також "записати" конфігурацію, яка в ті моменти, що ми маємо, як та, яка з'явиться за замовчуванням завжди або видалити існуючу. Ви також можете очистити "сканування" або недавнє сканування і, нарешті, вийти з інструмента.
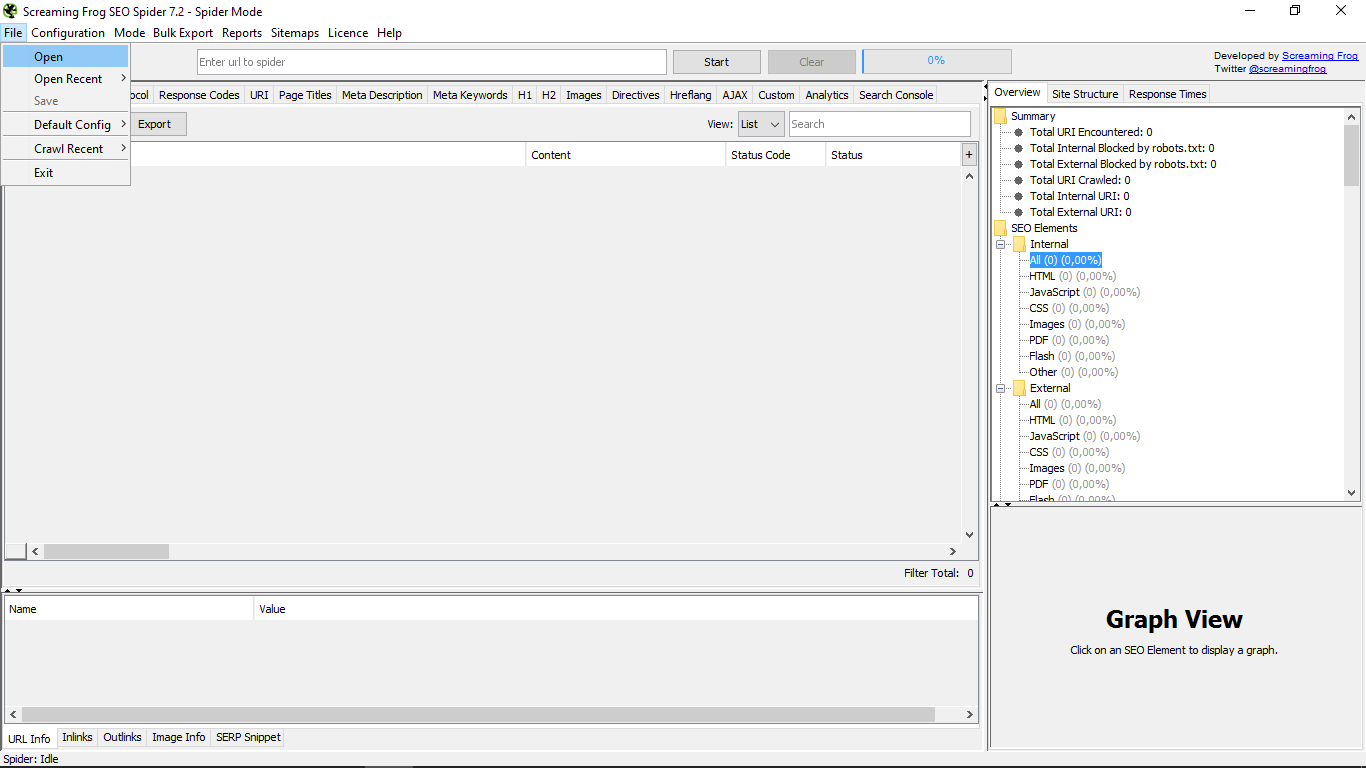
У "Конфігурації" в першу чергу є підменю "Павук", яке дає нам можливість вказати, як ми хочемо, щоб павук діяв на сайтах, які ми хочемо проаналізувати.
Існує кілька чинників, які ми можемо налаштувати залежно від того, що ми зацікавлені побачити або проаналізувати в кожному конкретному випадку.
Тут ми маємо, наприклад, в заголовку HTTP, опцію User Agent, яка дозволяє нам вирішувати, з яким типом "павука" ми працюватимемо.
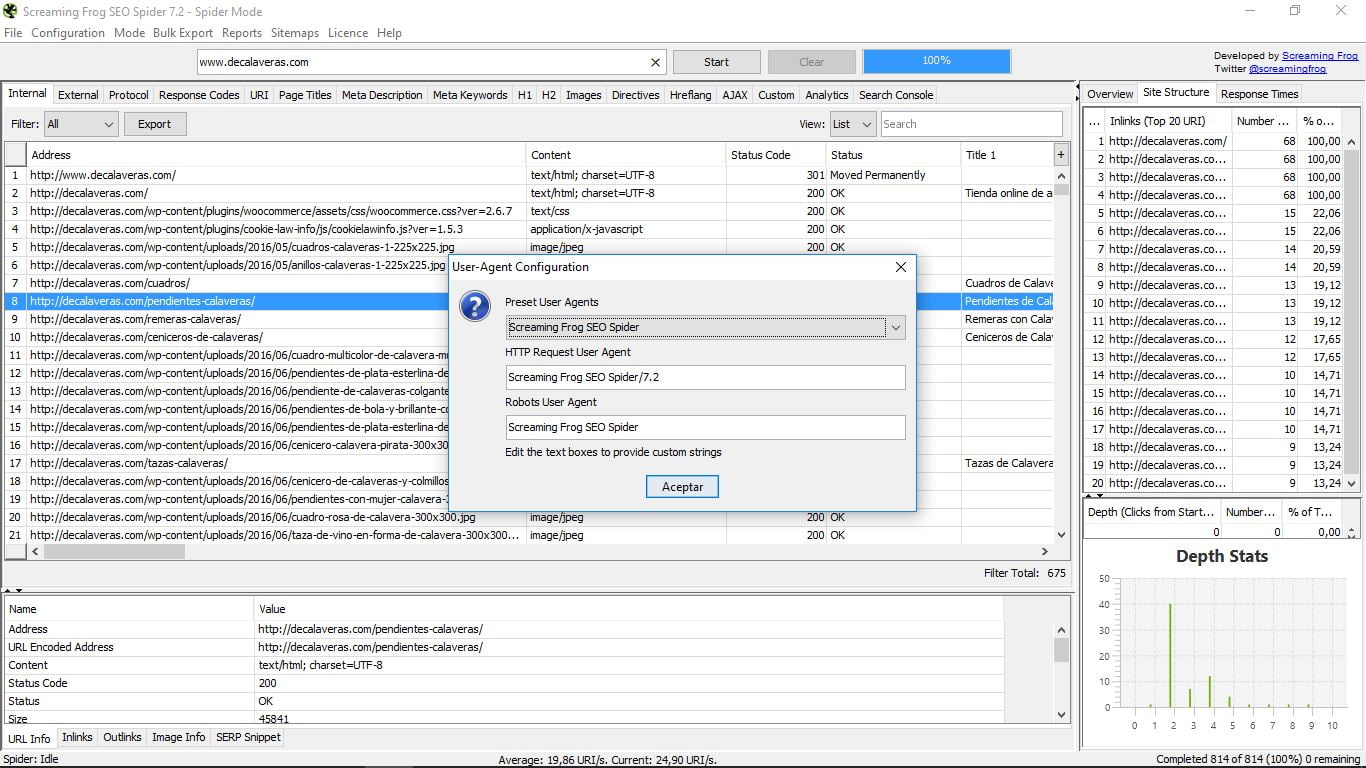
Це корисно, коли хостинг, де ми розміщуємо наш сайт, блокує доступ до павука Screaming Frog, і ми не можемо використовувати цей інструмент. Для вирішення проблеми просто використовуйте тренажер робота Google.
У "Robots.txt" ми можемо налаштувати, а також налаштувати поведінку павука з цим типом файлів.
У решті опцій ми маємо дуже різноманітні конфігураційні функції, серед яких зв'язок з API API і консолі пошуку або візуалізація інтерфейсу трохи більш дружній, стиль Windows. Ми працюватимемо над цим керівництвом Screaming Frog з нею за те, що буде більш впорядкованим і інтуїтивним.
У "Режимі" ми виберемо, яку основну функцію ми хочемо використовувати: павук, список або SERP. Потім ми детально розберемо їх, оскільки загальне меню змінюється в кожному випадку.
"Масовий експорт" дозволяє масово експортувати в документи формату CSV звіти про вхідні або вихідні посилання, зображення, якірний текст, а також налаштувати фільтри; у той час як у "Звіти" ми отримаємо доступ до підсумків відстеження та звітів про помилки з різними параметрами.
"Мапи сайтів" дають нам можливість створювати карту сайту, а також ваші зображення. Ці параметри зараз рідкісні, оскільки більшість інструментів для веб-керування включені. Якщо це не так, ви можете завантажити їх тут і надіслати їх до консолі пошуку Google.
"Ліцензія" - це посилання для оплати за версію "pro" та введення пароля після підписки.
Нарешті, у розділі "Довідка" ми маємо посібник користувача, деякі поширені запитання, контакт з підтримкою та відгуками, пошук і автозавантаження для оновлення інструментів, налагоджувальний відладчик і сторінку "Про програму". Допомога, яку ми сподіваємося, вам не потрібно використовувати після прочитання цього підручника 😉
3. Режим Павука
Перебуваючи в цій модальності інструменту, якщо ми введемо URL веб, ми зробимо повний аудит сайту.
Існує індикатор виконання, який показує у відсотках прогрес "сканування" всіх веб-сторінок, про які йдеться, як ви можете бачити на наступному знімку екрана. Існує можливість зупинити процес, а потім відновити його або безпосередньо видалити запит.
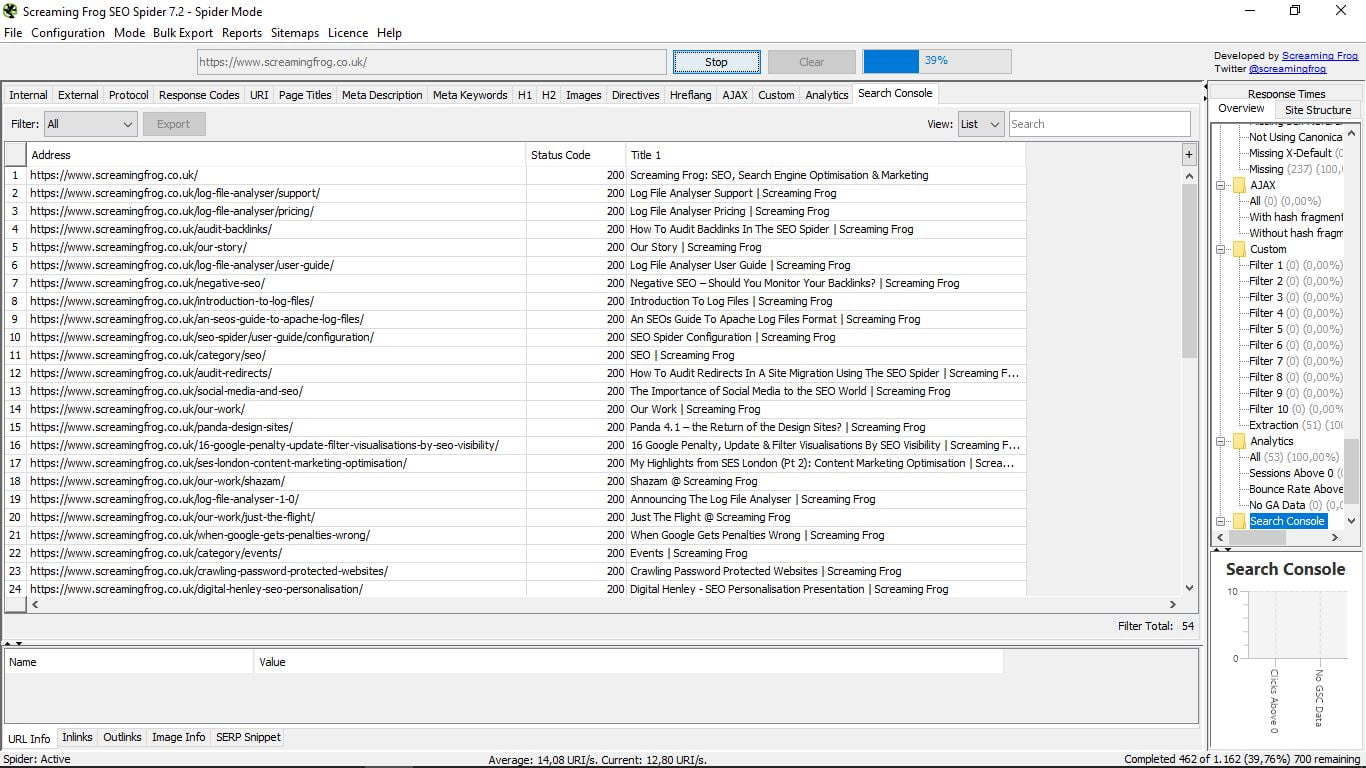
Давайте подивимося на внутрішній сайт власного сайту Screaming Frog.
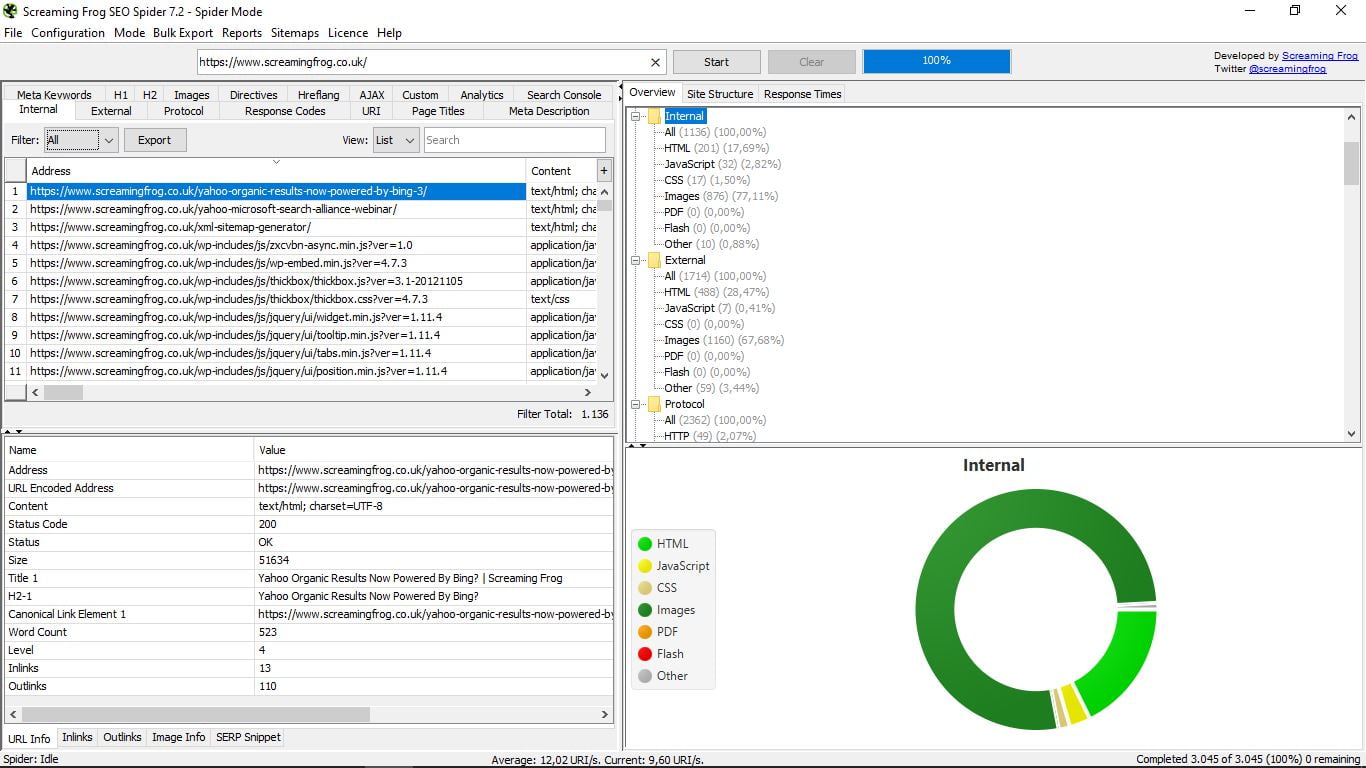
Коли завдання павука закінчиться (це займе більше або менше залежно від розміру веб-сторінки), ми дізнаємося загальна кількість сторінок, які є частиною вашого сайту. У цьому випадку вони становлять 3,045. З усіх них ми бачимо зараз нескінченні дані.
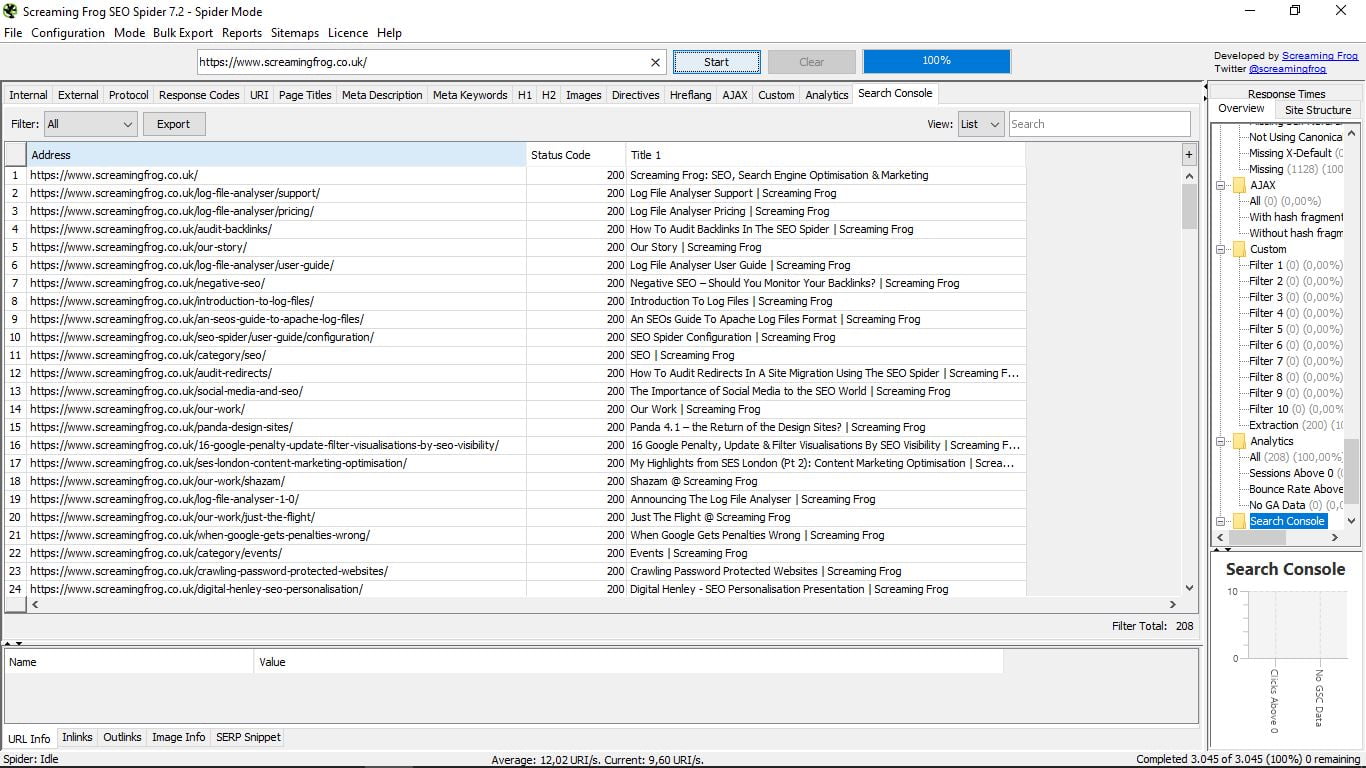
У нас є опція за замовчуванням, щоб показати все, але в "Фільтр" (ліворуч у вікні результатів) можна фільтрувати сторінки відповідно до типу вмісту: html, JavaScript, CSS, pdf, images, flash ... І будь-який з цих вибіркових пошуків або загальний обсяг можна експортувати (кнопка експорту)
Праворуч у вікні "Перегляд" ми можемо вибрати перегляд за списком або за допомогою дерева папок, а також виконати в рядку "Пошук" пошук за словом, щоб знайти певну адресу.
У таблиці також можна сортувати результати за типом вмісту, його кодом статусу та його назвою.
Коли ми натискаємо певний URL, ми побачимо, що нижче ми можемо розгорнути вікно, де він надає нам всю інформацію про нього:
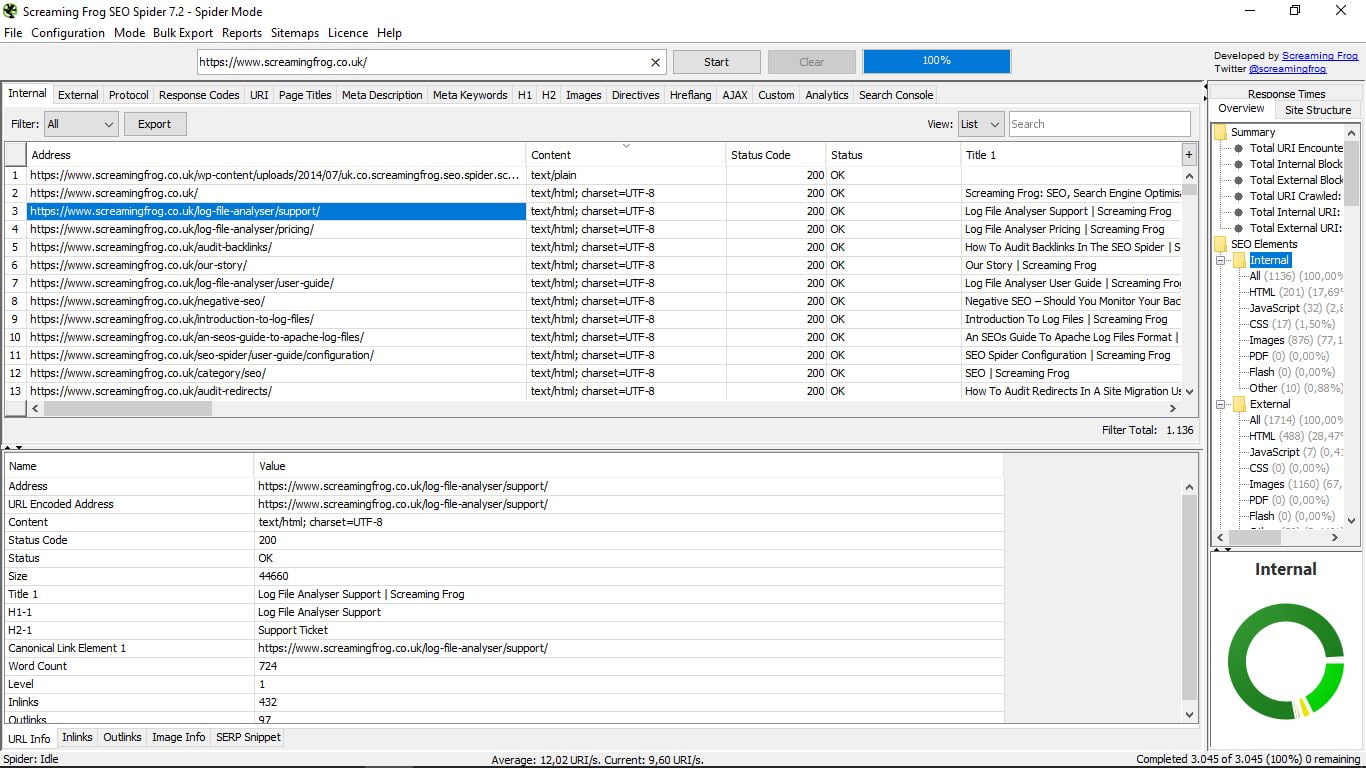
У цьому ж вікні ми маємо інше підменю, яке дозволяє вибрати, який тип даних показує:
- Інформація про URL, яка є типовою і містить адресу, тип контенту, стан, розмір, назву, першу частину H2, канонічне посилання, кількість слів, рівень, кількість посилання внутрішні і зовнішні.
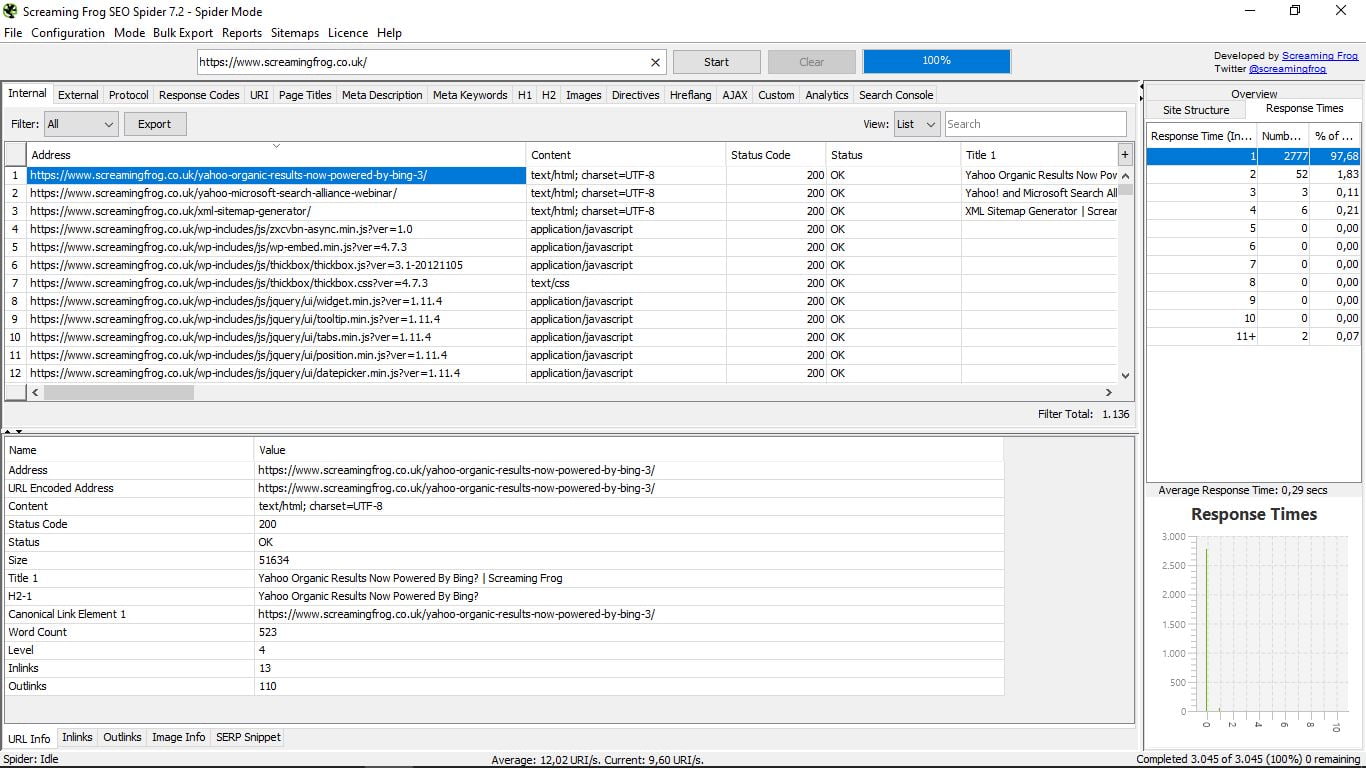
- Inlinks (внутрішні посилання), який показує нам тип посилання, куди ви йдете і куди ви йдете, якір tex t, текст Alt (якщо у нього є), і якщо вони виконуються чи ні.
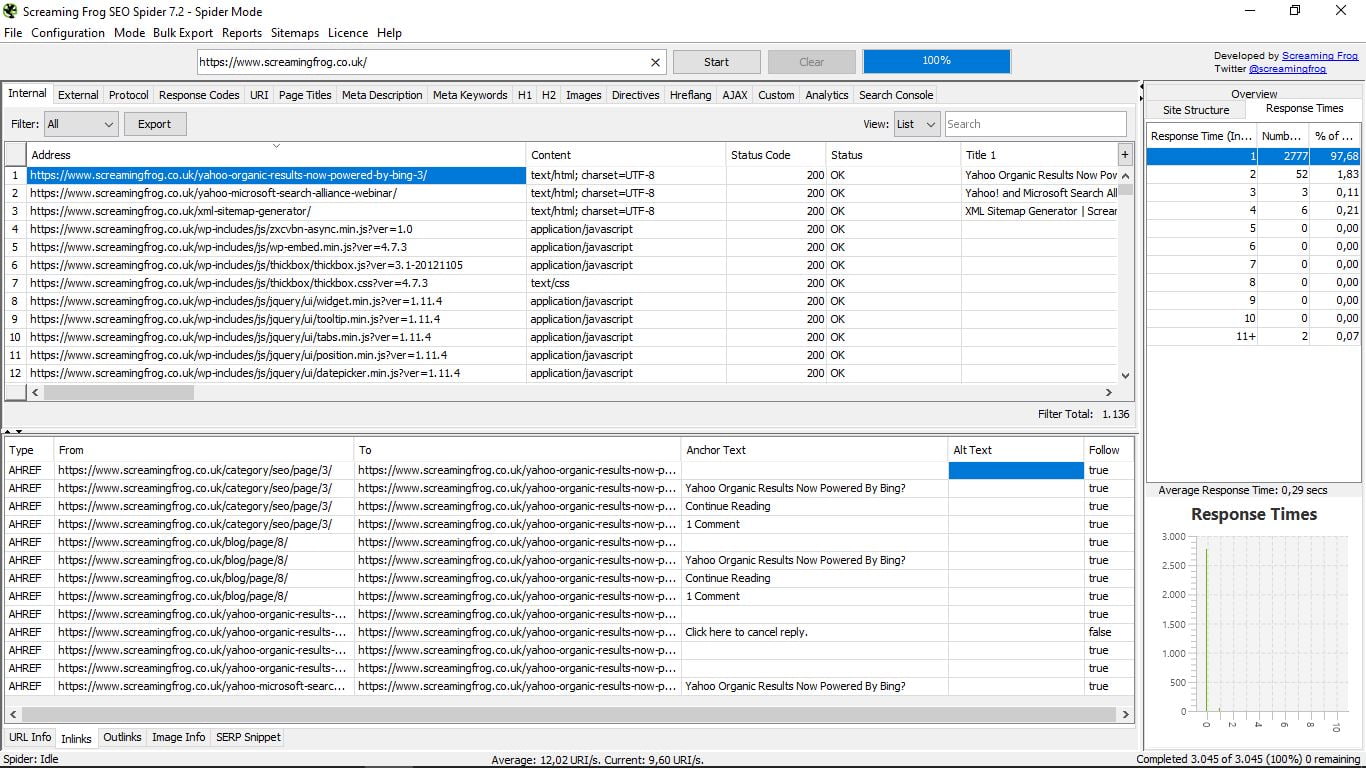
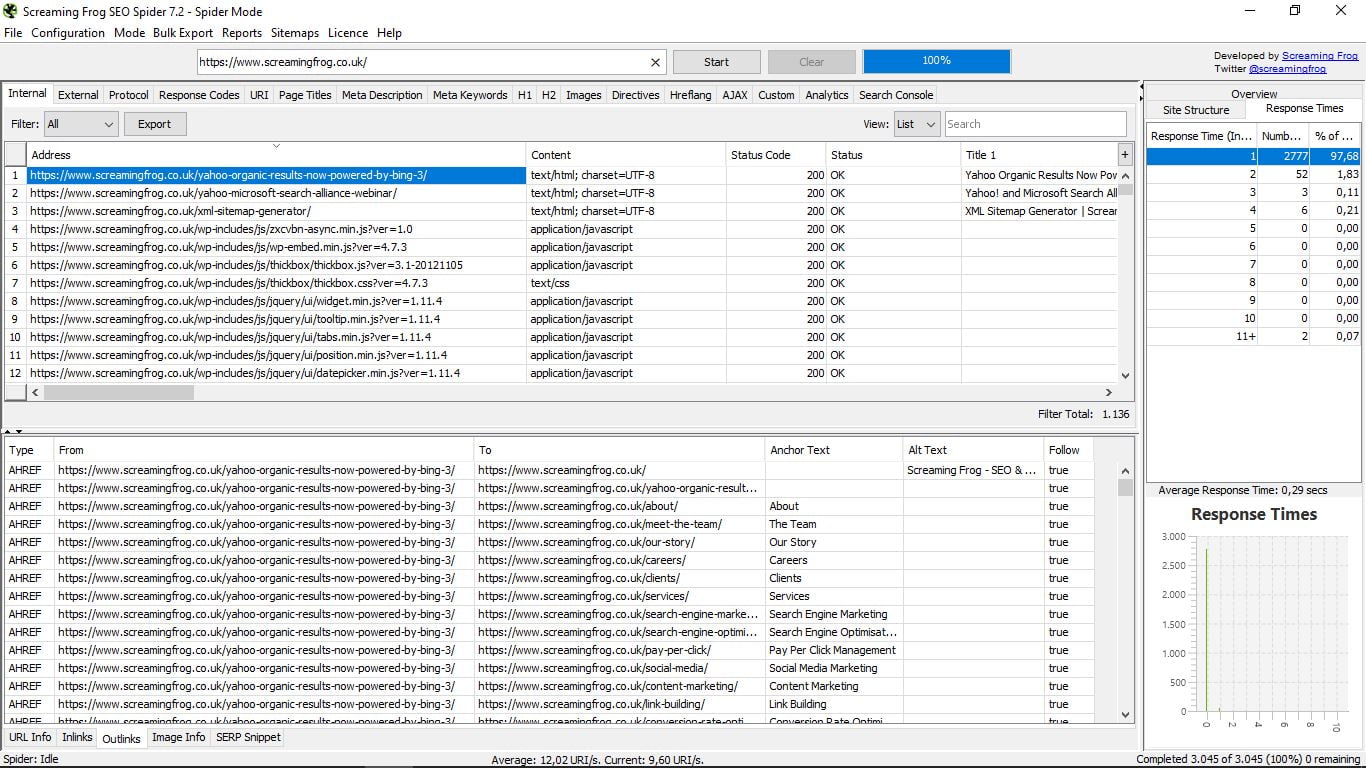
- Посилання. Точно таку ж інформацію, як Inlinks, але для зовнішніх посилань.
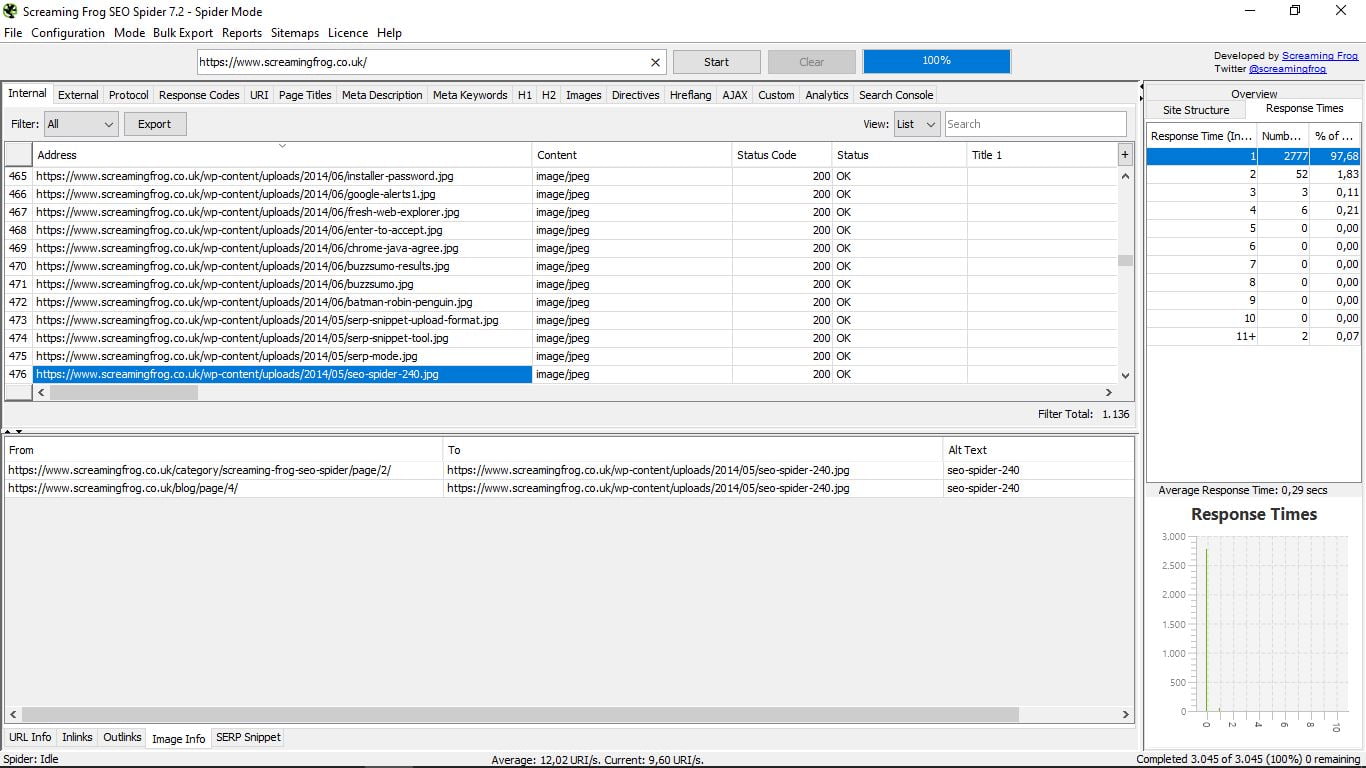
- Інформація про зображення: інформація про пов'язані зображення, що містяться на цій сторінці, де вона вказує, і Alt Text.
- Фрагмент SERP. Подивіться, як виглядає ця сторінка в пошуках Google. Вона дозволяє переглядати її для настільних, мобільних і планшетних пристроїв і включає в себе симулятор, з даними символів і пікселів для назв і описів, ключових слів, Багаті фрагменти (Відгуки, люди, події) з зірками або без них ...
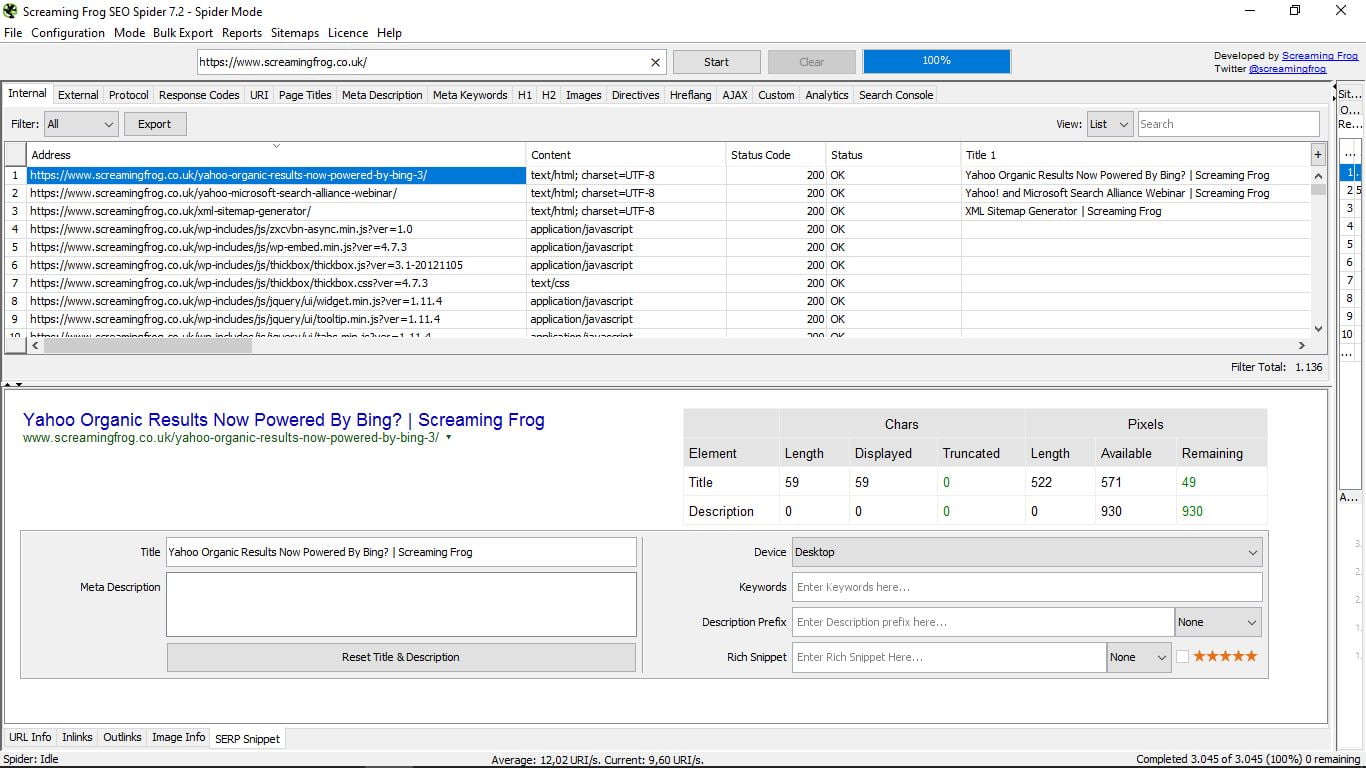
До всього цього, якщо ви помітили, праворуч від заявки, у вузькій колонці, яку можна розширити, у нас є три варіанти, які ми завжди можемо розглянути під час консультацій.
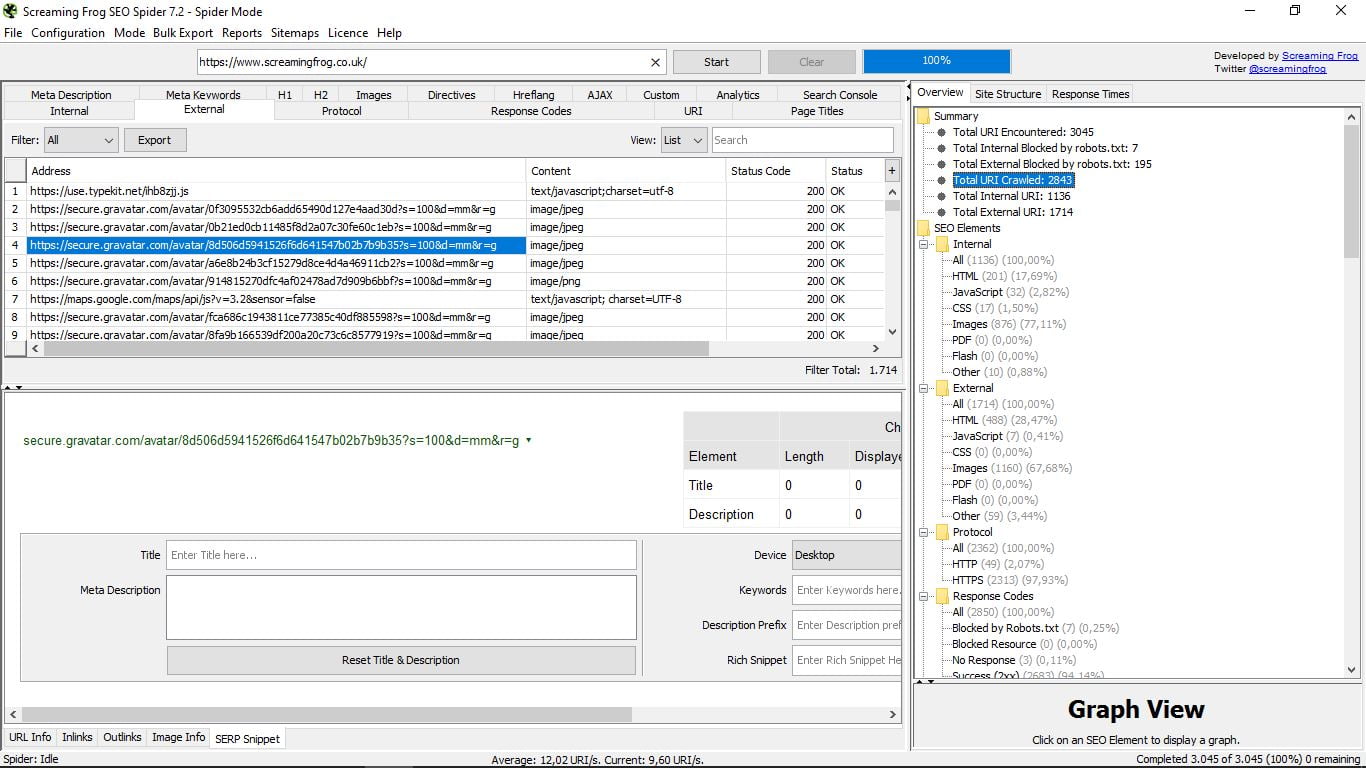
- Огляд, загальний вигляд у деревоподібному форматі з папками і підпапками, що показує в кожному випадку різні компоненти кожної інформації, яку ми шукаємо, з загальним числом і відсотковим. Наприклад, перебуваючи у Внутрішньому, повідомляє нам, як ви можете бачити на скріншоті, що є в цілому 1136 сторінок, з яких 200 є Html і становлять 17,69% від загальної кількості; зображень: 876 (77,11%) тощо ...
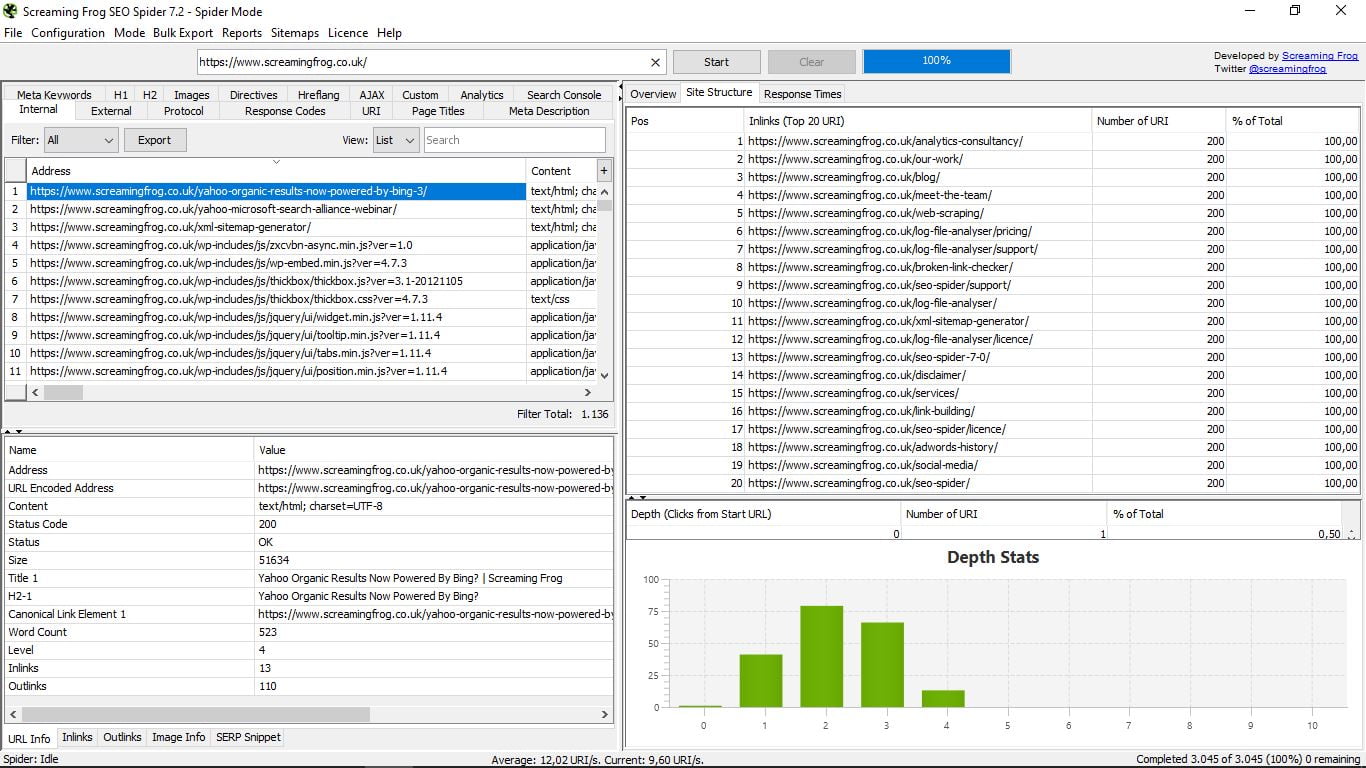
- Структура сайту, з 20 найпопулярнішими URL-адресами і статистикою глибини, тобто відстані, на якій кожна сторінка розташована від основного URL або домашнього, що рекомендується не більше 3 кліків.
- Час відповіді, який вказує час завантаження кожної сторінки за діапазонами. Ми повинні намагатися завжди бути найменшими, але якщо ми витрачаємо 4 секунди, ми повинні це виправити. Ми також бачимо середній час завантаження всього Інтернету.
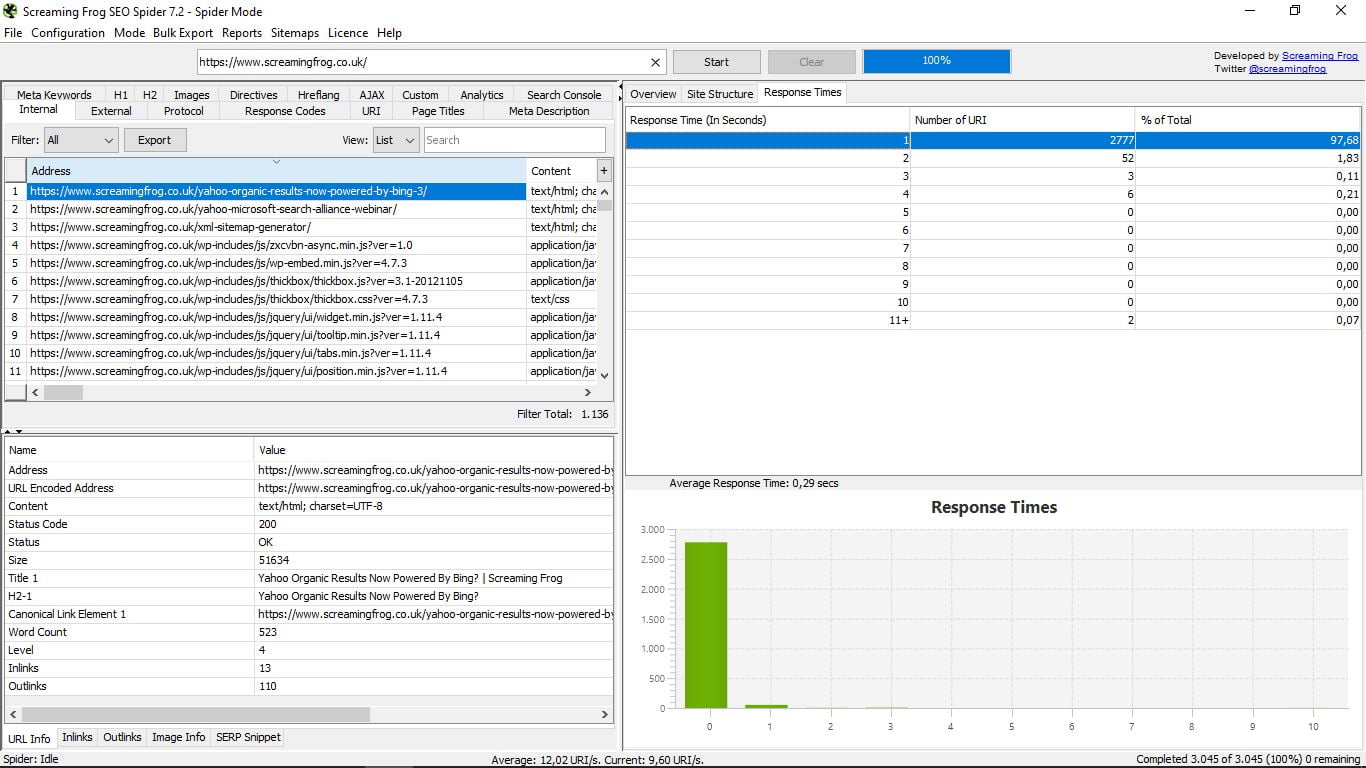
Ці три функції, як ви бачили, супроводжуються в нижній частині графікою. Це єдиний візуальний елемент, який ми знаходимо в Screaming Frog Seo Spider.
Щойно ми побачили всі можливості, які пропонує Павук, ми бачимо, що у нас є до 17 розділів, де ми бачимо конкретні дані з вказаного веб-сайту.
До цих пір ми дивилися на інформацію про внутрішніх сторінках, яка є типовою. Але натисніть будь-який інший варіант, щоб дізнатися, що нас цікавить.
3.1 Зовнішній
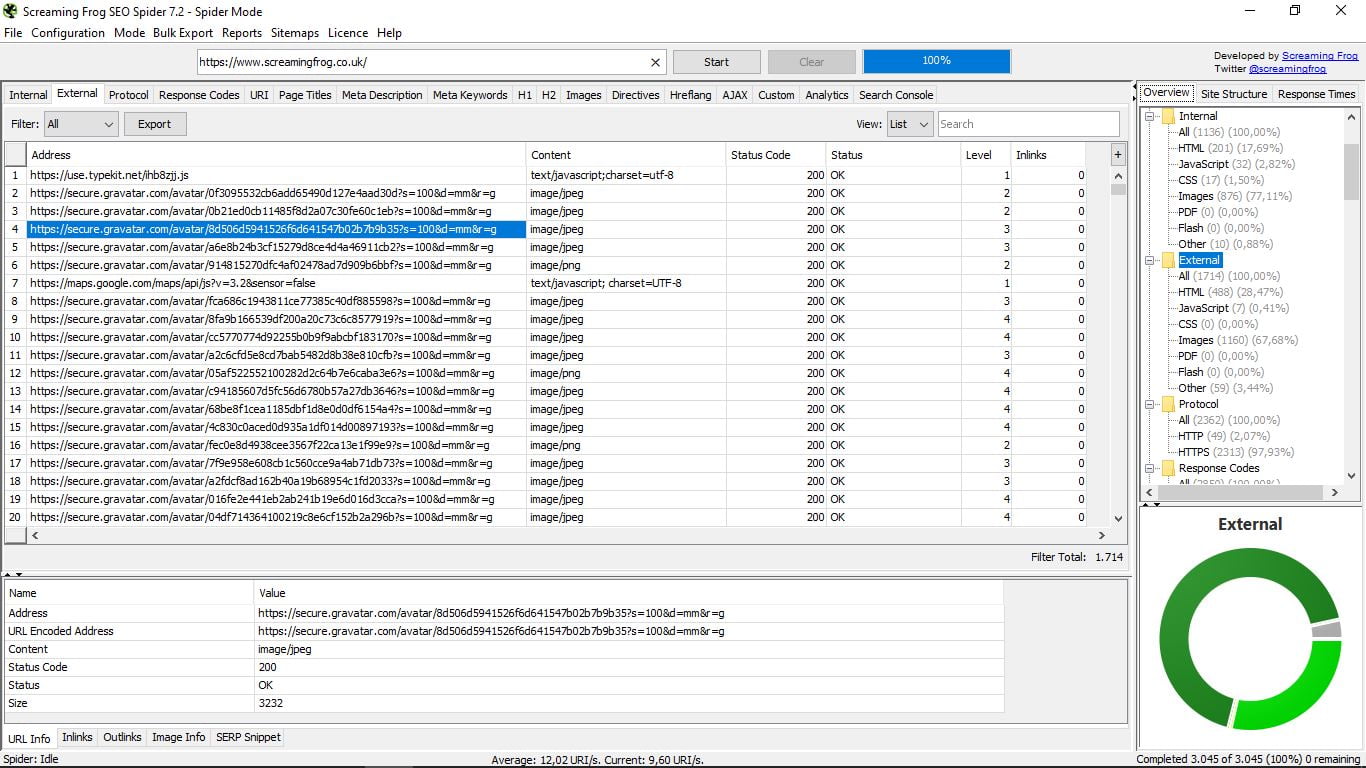
У ньому перераховані зовнішні сторінки домену нашого пошуку, його тип (якщо це Html, зображення, CSS, JavaScript, PDF, Flash, інші ...), код його статусу (200 Ok, 301, 404 ...), його рівень і його внутрішні посилання
Пам'ятайте, що праворуч у вас є стовпець з більш загальними варіантами і його графікою, а нижче всього інші п'ять функціональних можливостей, щоб побачити конкретну інформацію кожного з URL-адрес. Це стосується в усьому, що ми побачимо.
3.2 Протокол
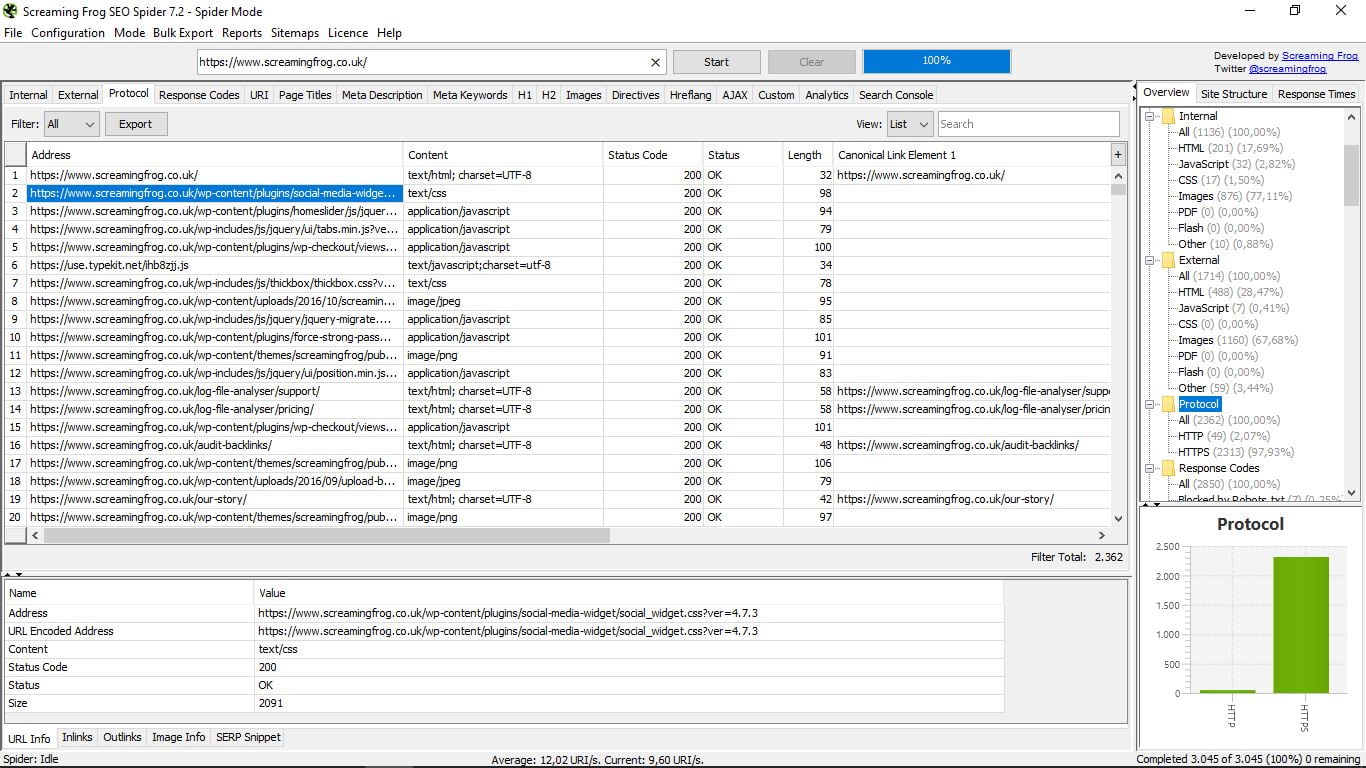
Ми побачимо сторінки відповідно до їх протоколу безпеки (http або https), а також конкретну інформацію про кожну з них (url, тип формату, статус і код стану, довжину, головну канонічну посилання).
3.3 Коди відповідей
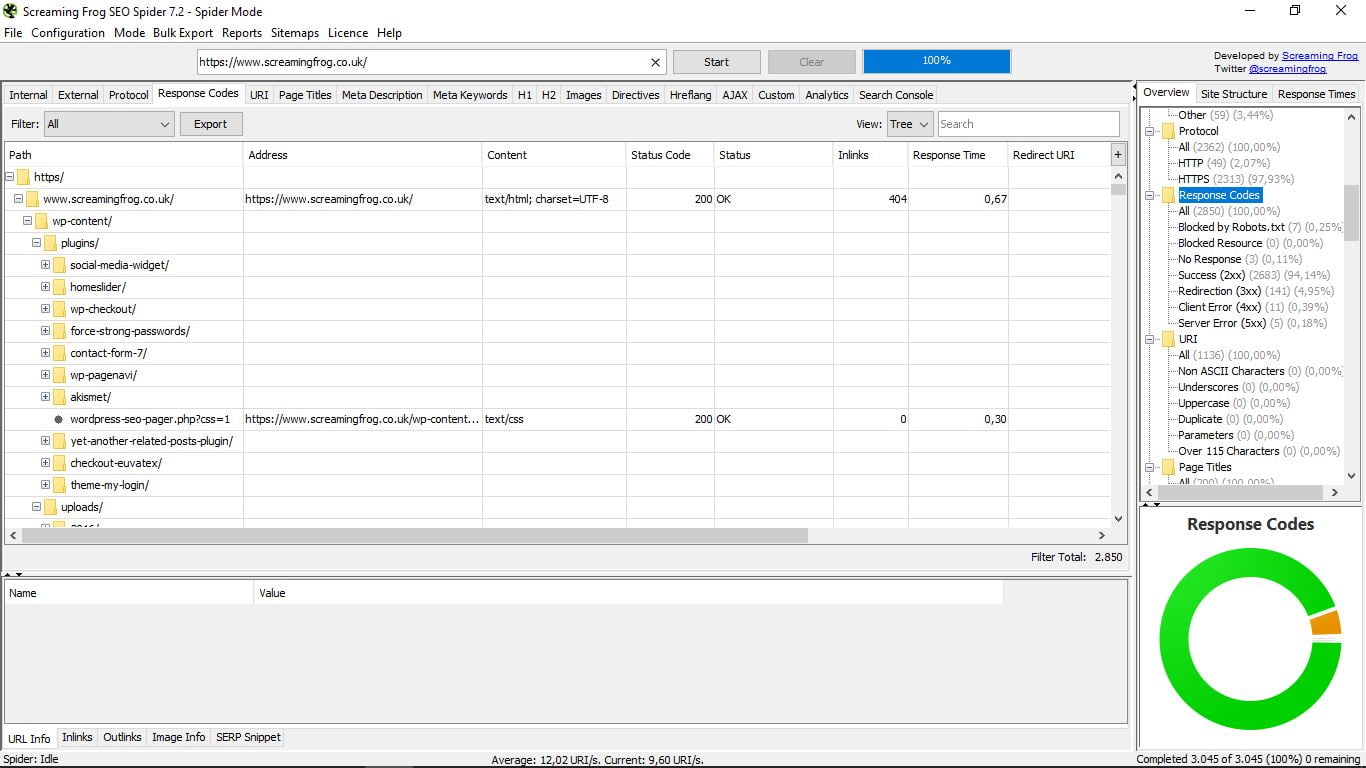
Щоб побачити коди відповідей сервера, краще вибрати деревоподібний вигляд замість списку, який приходить за замовчуванням, як ми бачили. Таким чином, ми краще виявимо сторінки, заблоковані файлом Robots.txt, заблоковані ресурси, URL-адреси, які не реагують, ті, що роблять, перенаправлені і ті, які надають помилку клієнта і помилку сервера.
Виправлення або усунення тих, які дають ці помилки 4XX або 5XX, є необхідним для оптимізації нашої сторінки.
3.4 URI
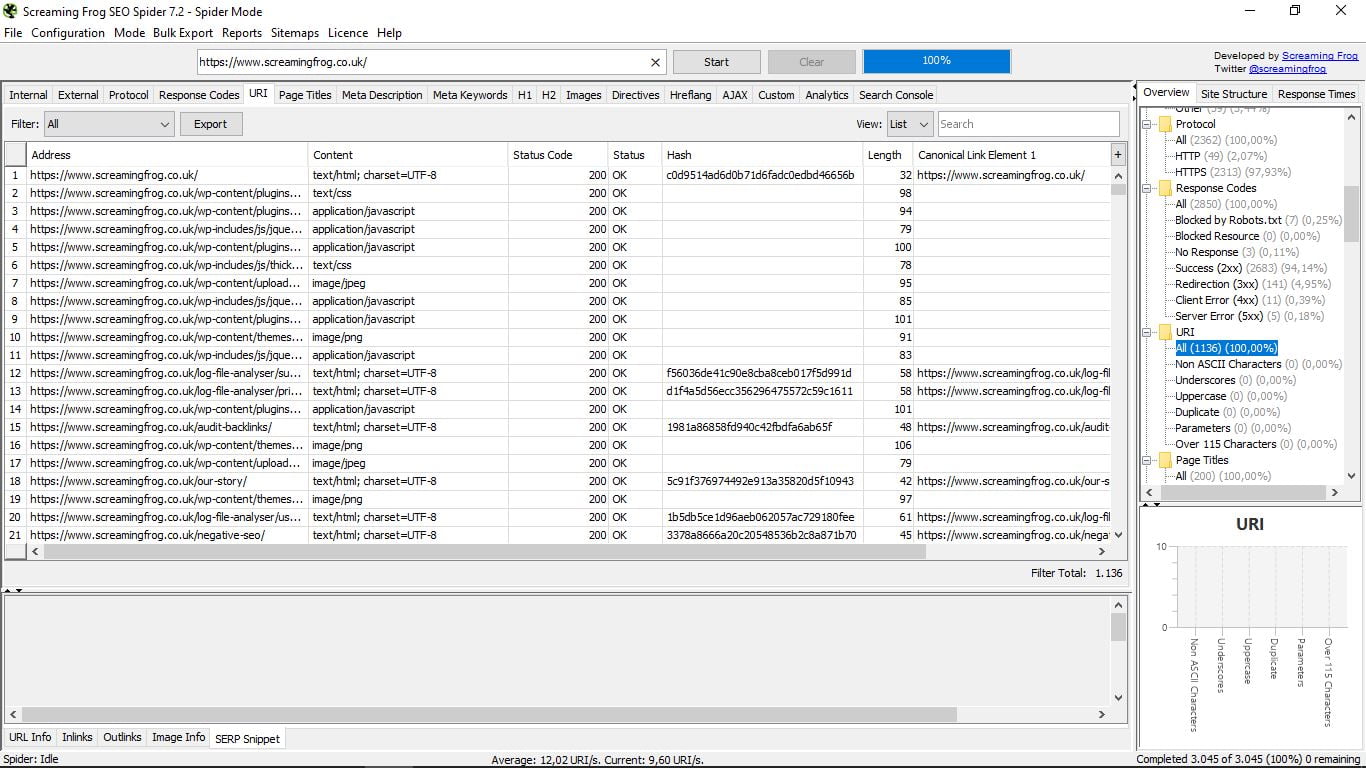
Технічний розділ для перегляду адрес відповідно до уніфікованого ідентифікатора ресурсів (URI): без символів мови ASCII, символів підкреслення, великих літер, дублікатів, параметрів і більше 115 символів.
3.5 Назва сторінки
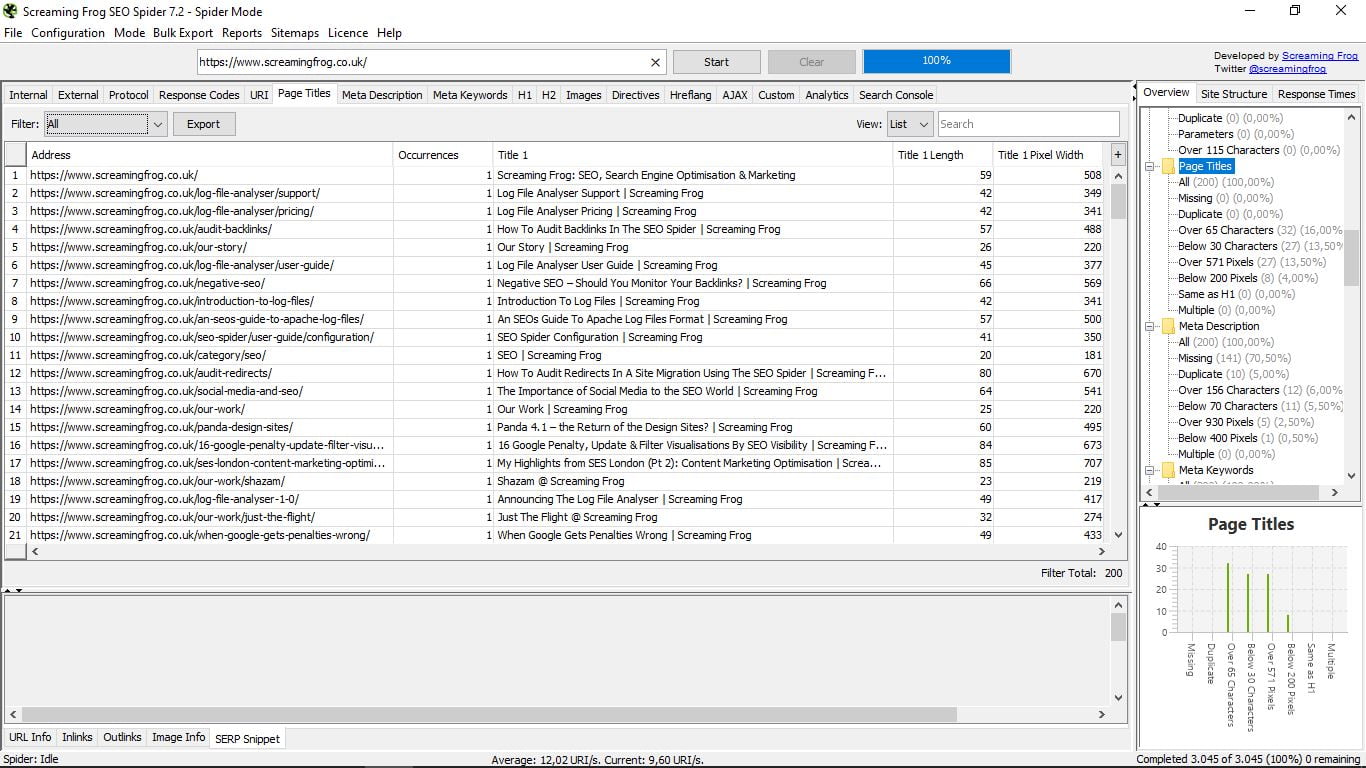
Місце, де ми зможемо побачити з першого погляду всі назви наших сторінок, їх довжину і ширину в пікселях. Корисно для виявлення сторінок без них або з дублікатами, що перевищують 65 символів або нижче 30 (зупинки, рекомендовані Google); вище 571 пікселя або нижче 200; те ж, що H1; або кілька.
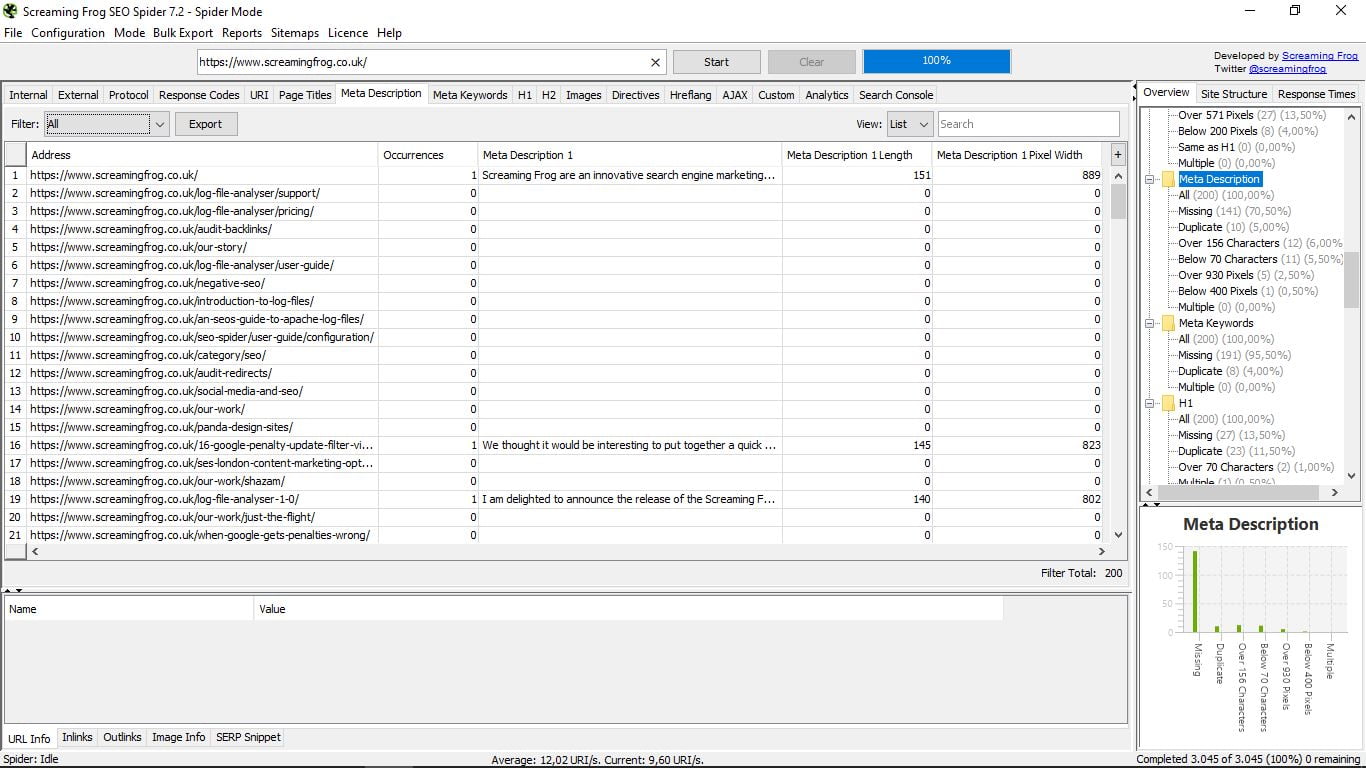
Тут ми побачимо мета-описи кожної з наших сторінок, а також їх довжину і ширину в пікселях.
Як і в попередньому розділі, це дозволяє нам бачити, скільки сторінок немає, скільки має дублікатів, вище 156 символів або нижче 70; або вище 930 пікселів і нижче 400; і скільки їх багато.
Ще раз нагадуємо, що ви можете фільтрувати за допомогою параметра "Фільтр", що знаходиться ліворуч від вікна зі списком URL-адрес, або стовпцем праворуч.
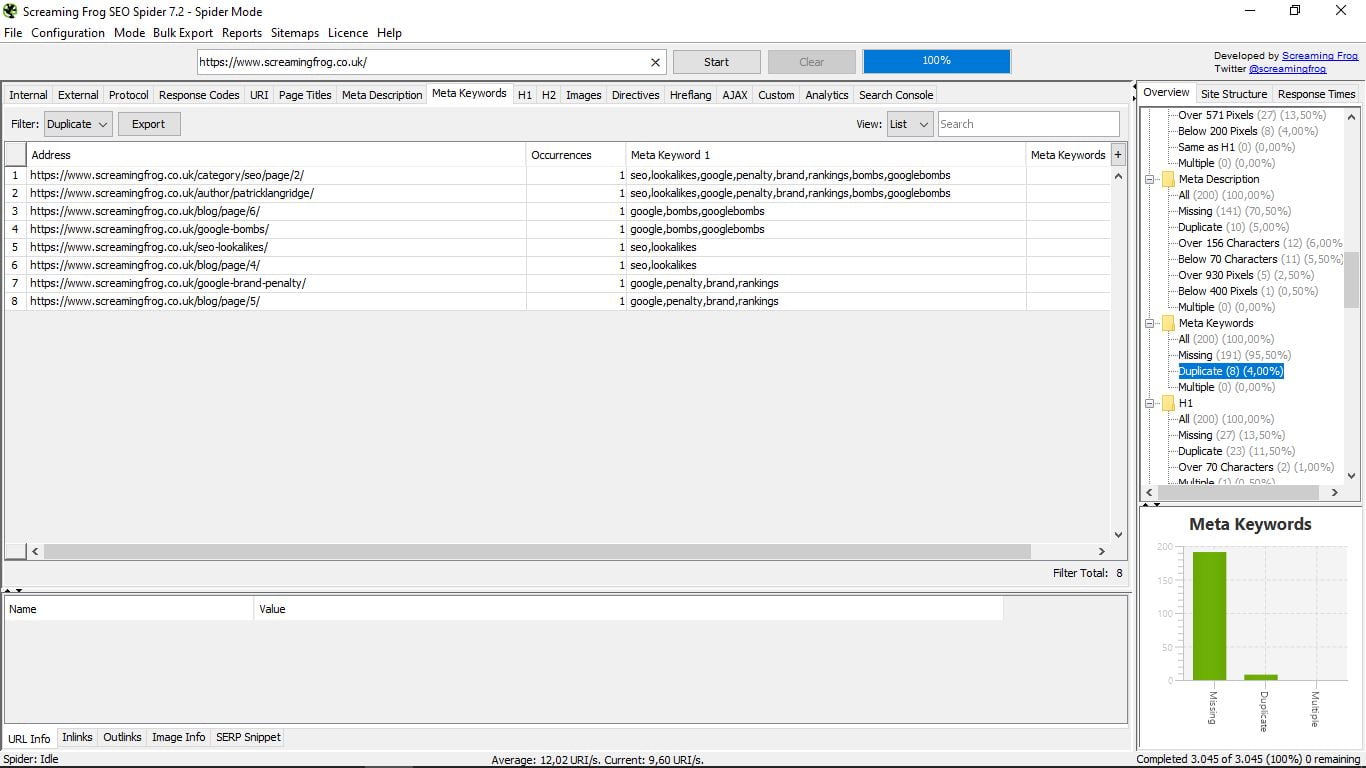
Ця функція правда полягає в тому, що вона застаріла, оскільки Google перестала враховувати мета-ключові слова навряд чи хтось використовує їх. Але, ну, є якщо хтось цікавиться, які сторінки і які використовують (або скоріше використовують) свою компетентність.
3.8 Етикетка H1
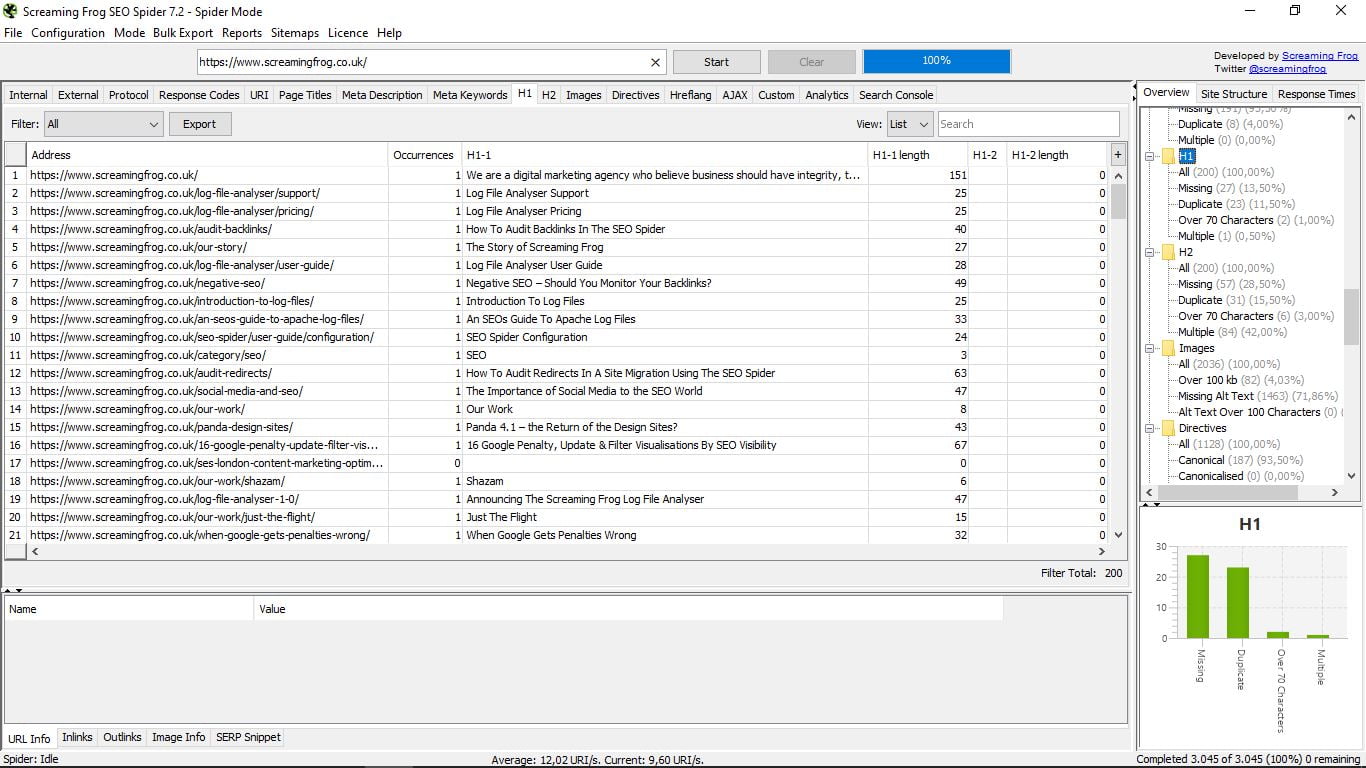
Ми перейшли від секції без корисності до однієї зі столичної важливості. Тут ми показані H1 кожної з наших сторінок (або конкурсу, відповідно до сайту, з якого ми виконали пошук).
Вона вказує на довжину в символах і якщо є більше однієї сторінки (не рекомендується). З колонкою праворуч можна з легким поглядом дізнатися, скільки сторінок не має H1, скільки є дублікатів, які перевищують 70 символів і декілька випадків.
3.9 Мітки Н2
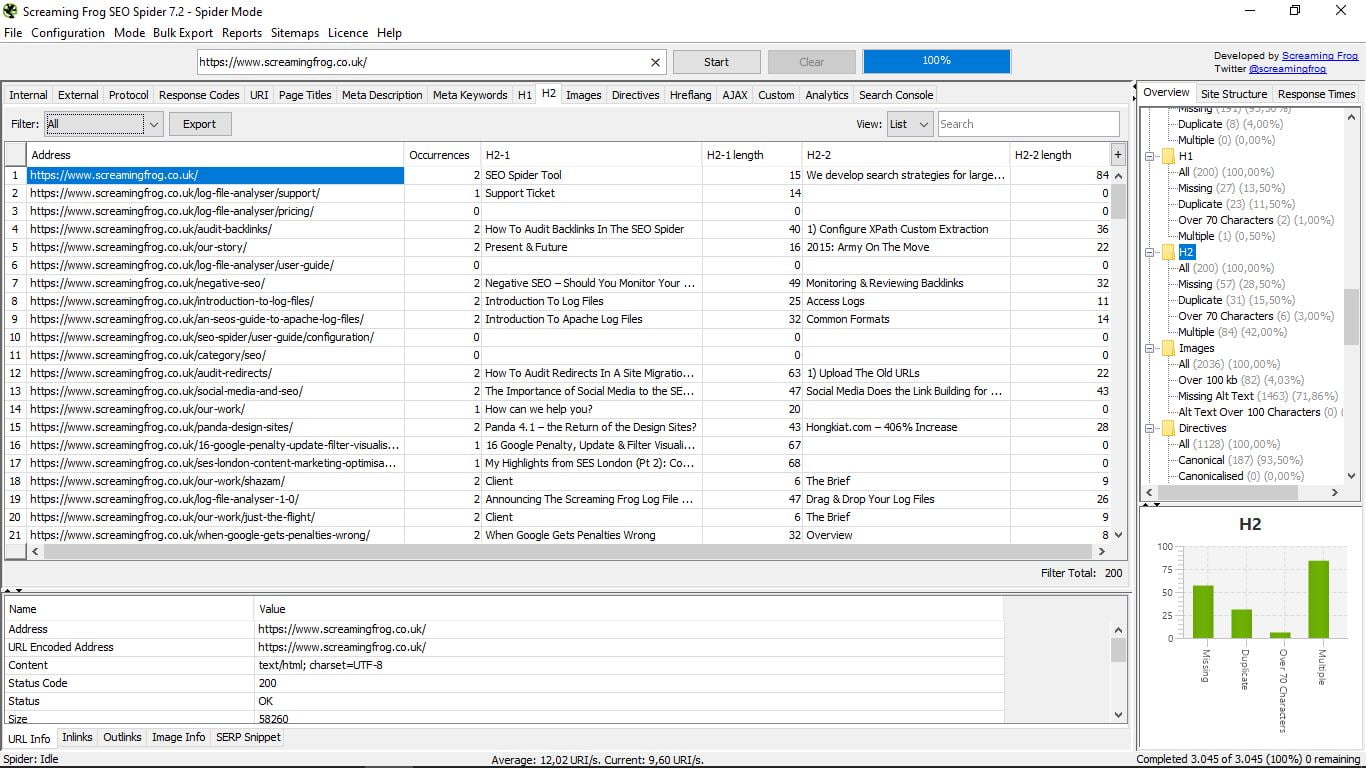
Точно так само, як і попередній, але тепер для H2, де істотна різниця в тому, що H2 може мати більше одного без будь-яких проблем. Тут показані перші дві для кожної сторінки.
3.10 Зображення
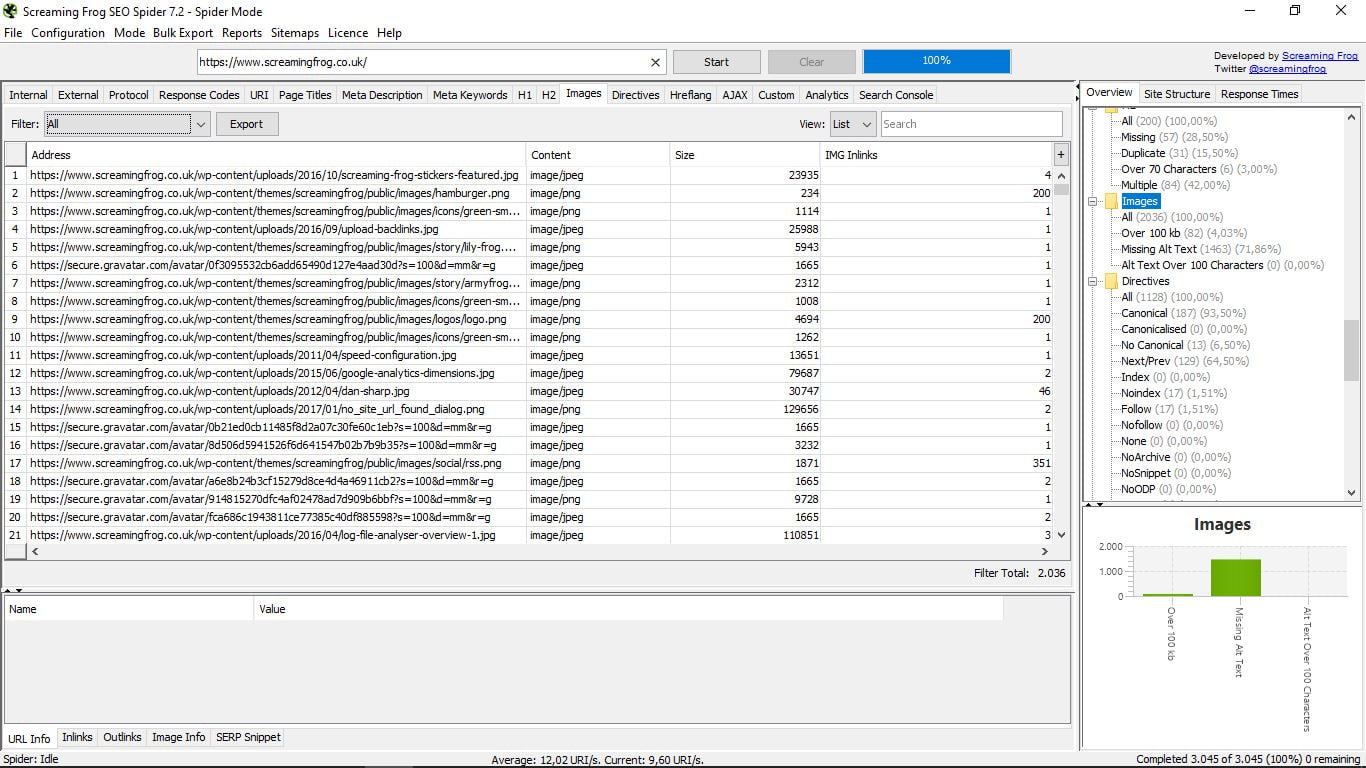
Він рентгенографізує всі зображення мережі, вказуючи її адресу, її формат (PNG, JPEG ...), його вагу в Кб і внутрішні посилання. Праворуч або у фільтрах можна знайти ті, які важать більше 100 кб, ті, які не мають Alt Text, або ті, в яких вона перевищує 100 символів.
3.11 Директиви
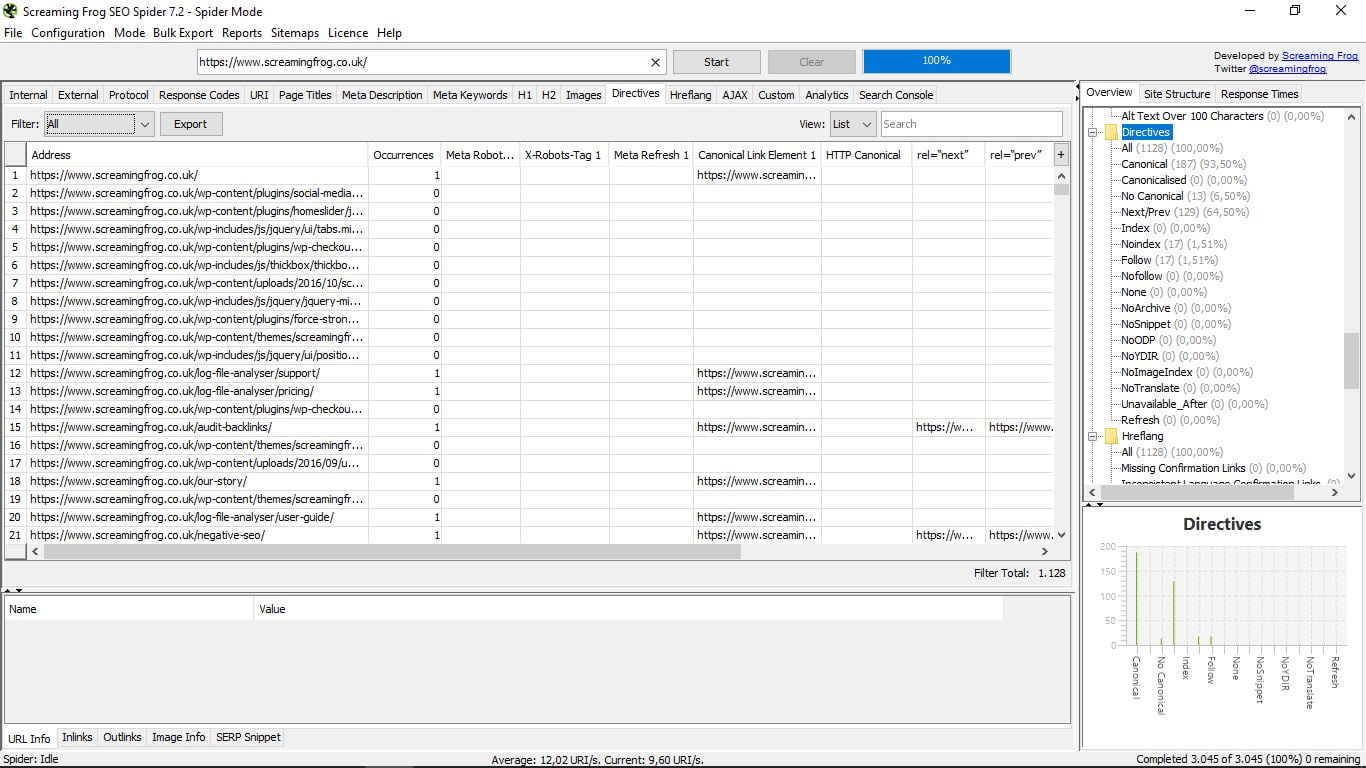
Ми будемо знати тут директиви, які регулюють для кожної сторінки (канонічний, наступний-попередній, індекс / без індексу, слідувати / nofollow, не перекладати ...). Ви можете звернутися до довгого списку праворуч, з відповідним відсотком і графіком, або безпосередньо у вікні списку результатів.
3.12 Етикетки Hreflang
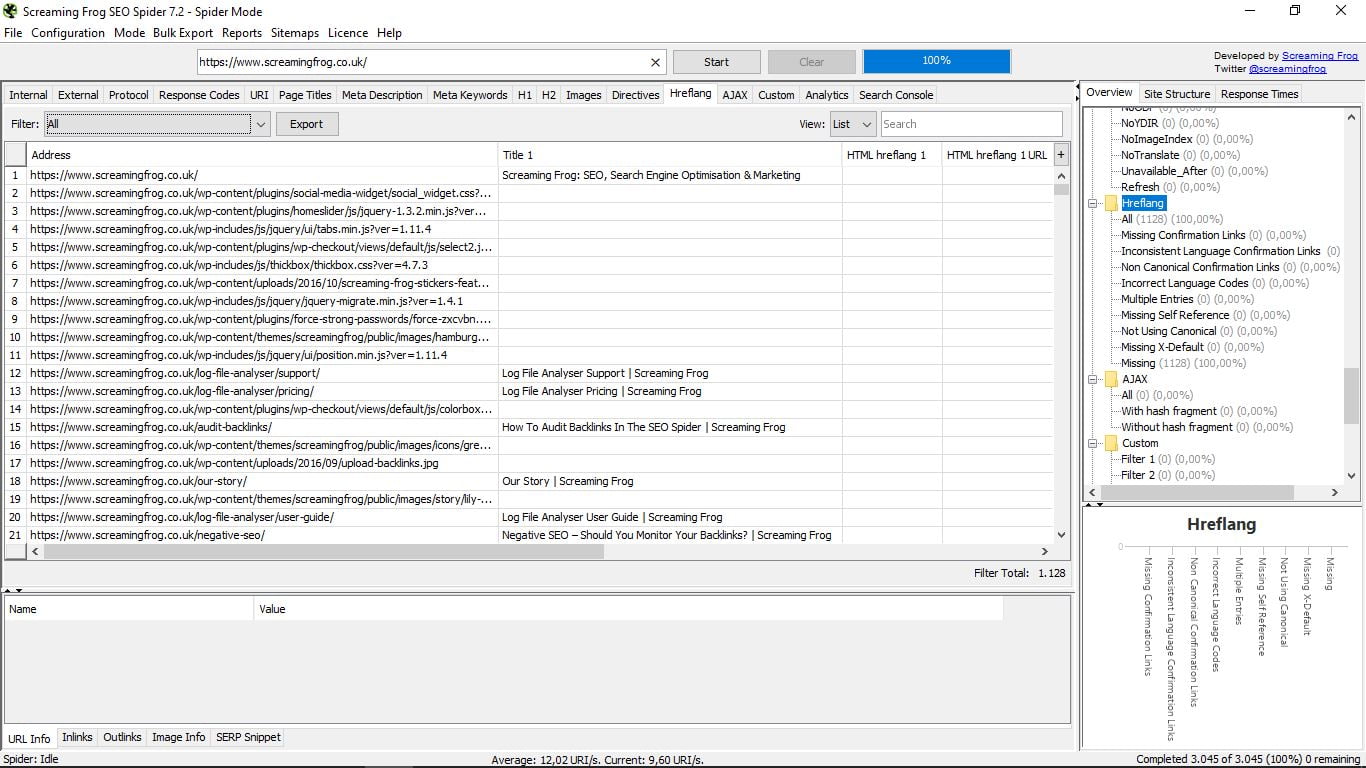
Якщо ви позначили свою сторінку як багатомовну в консолі пошуку Google, ви матимете теги Hreflang. Цей розділ визначає їх і попереджає про можливі помилки. Звичайно для реалізації цих тегів не вдається.
Тут ви легко побачите, що не вдається в кожному випадку: якщо це не взаємно, якщо немає канонічного або X-за замовчуванням, і т.д.
3.13 AJAX
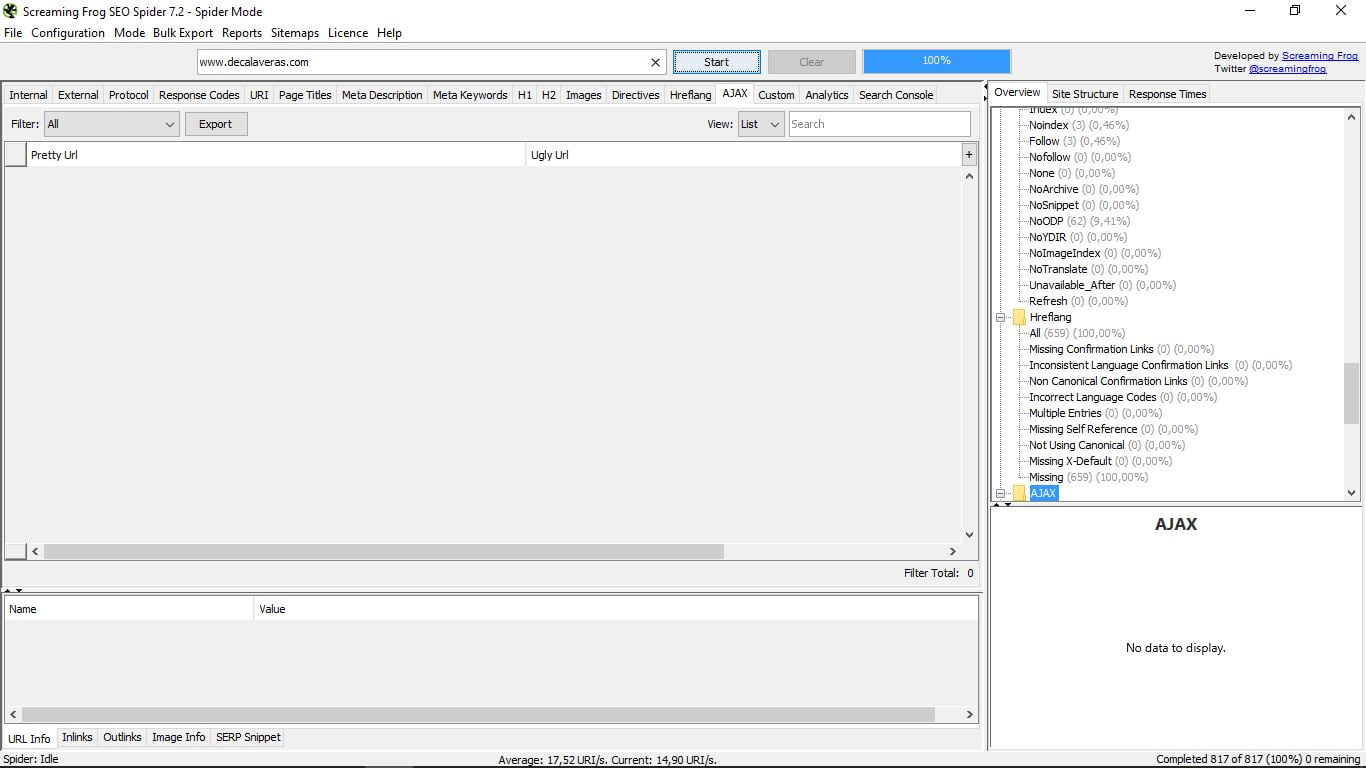
Немає нічого спільного з миючим засобом, ні з футбольною командою Амстердама; _) Вони являють собою скорочення асинхронного JavaScript і XML (асинхронний JavaScript і XML) і це техніка веб-розробки, яка використовується для створення інтерактивних додатків.
Звичайний, якщо ваш веб-сайт "нормальний", полягає в тому, що цей розділ порожній, як у випадку з прикладом.
3.14 Користувальницькі
Це розділ для пошуку за допомогою спеціальних фільтрів. Для цього їх потрібно налаштувати раніше. Це робиться в головному меню "Конфігурація" і всередині нього в "Користувацькому":
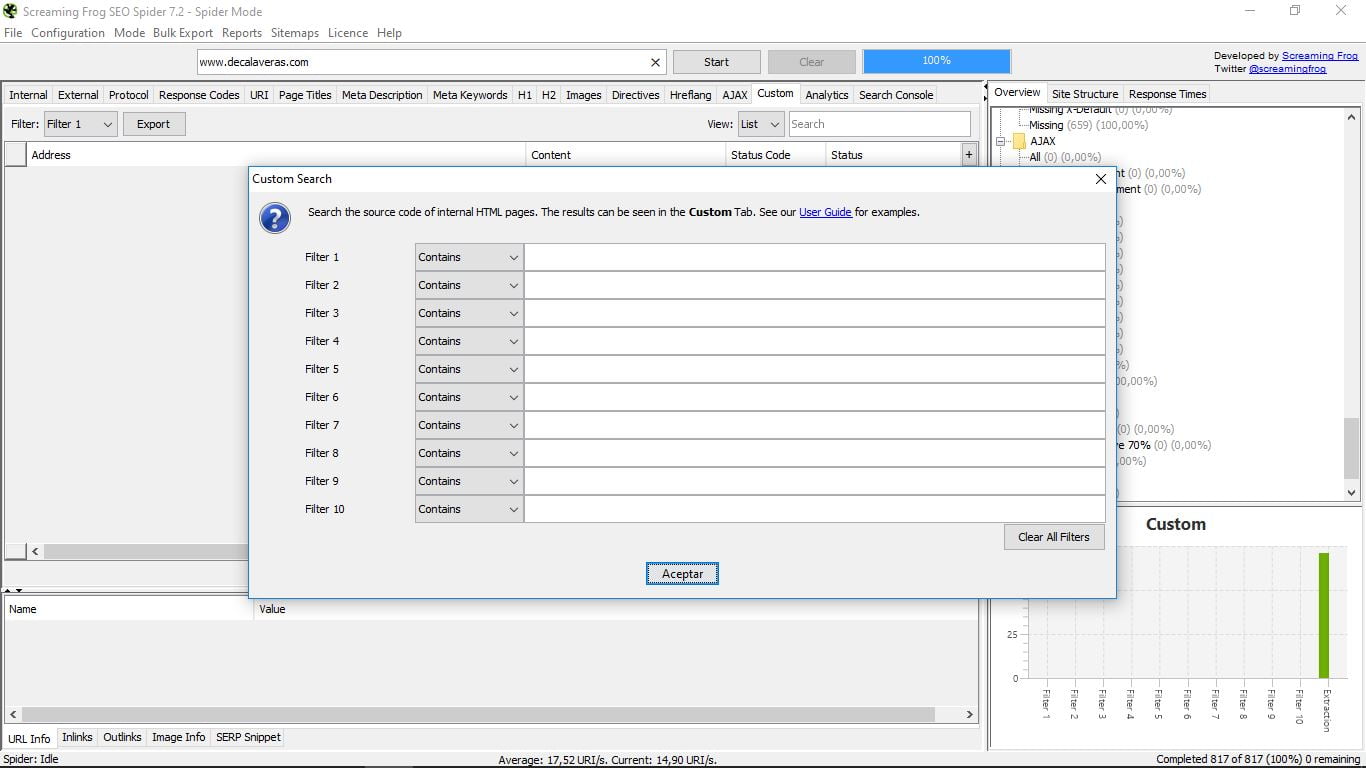
Там у нас є можливість "Пошук", тобто пошук, або "Видобуток", щоб отримати певні елементи наших внутрішніх сторінок Html. В обох випадках ми повинні вибрати потрібні параметри та зберегти їх, щоб потім виконати пошук з "Custom".
3.15 Аналітика
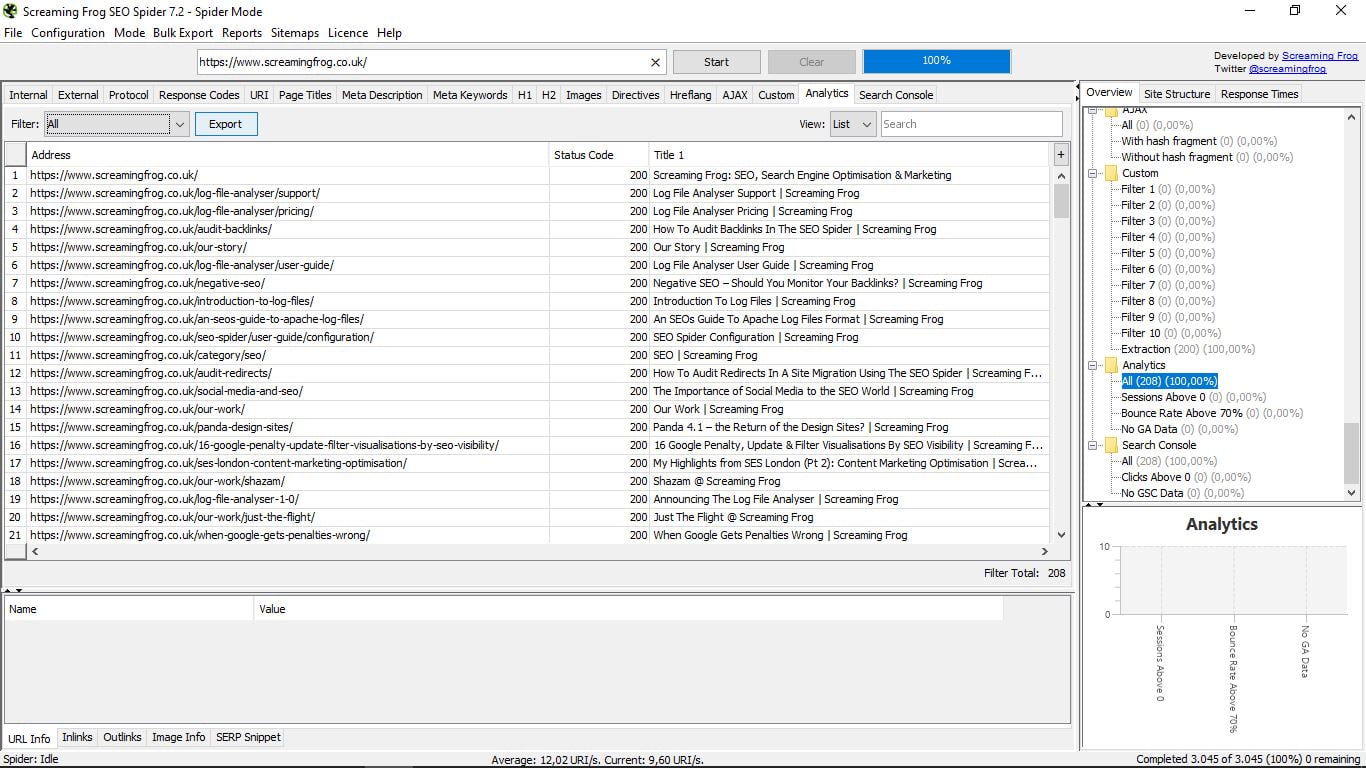
Під час підключення інструмента з Google Analytics ми бачимо попередні сесії, показники відмов вище 70% або дані, які не містять даних Analytics.
3.16 Консоль пошуку
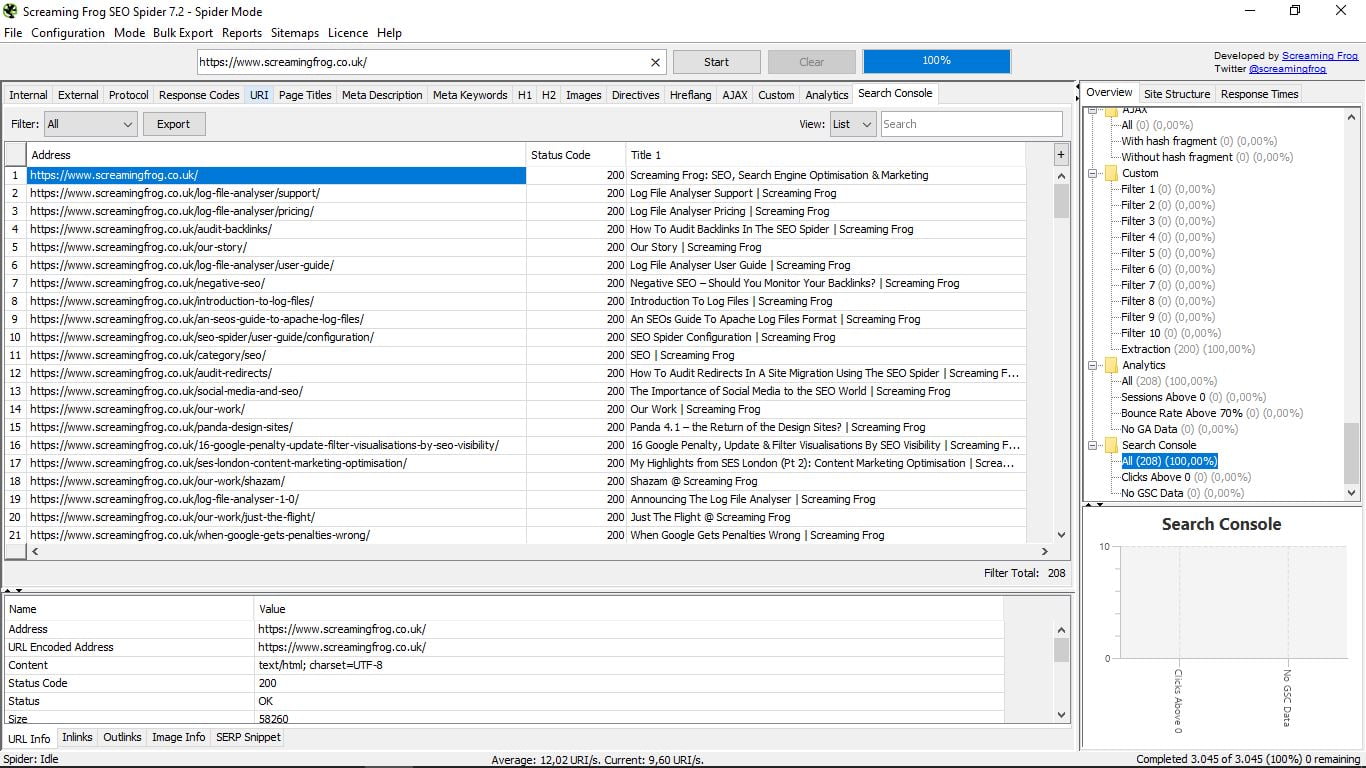
Те ж, що й у попередньому, але в цьому випадку для інструменту Google Search Console.
4. Режим списку
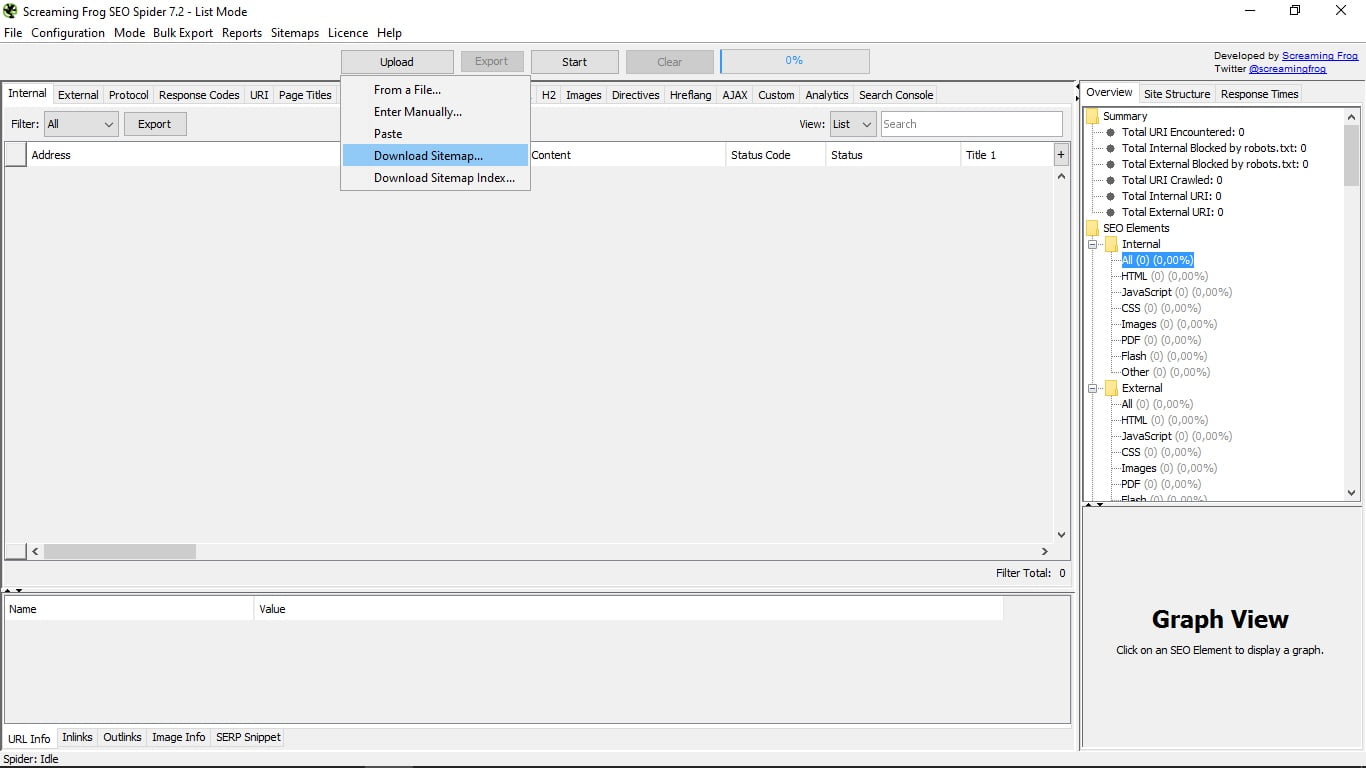
Тут те, що дозволяє нам інструмент завантажувати собі список URL-адрес, які ми зібрали в документі. Існує також можливість ввести їх вручну, вставити або завантажити з мапи сайту або індексу мапи сайту URL-адреси, яку ми вам повідомляємо.
Звідси функції інструмента такі ж, як і в режимі павука.
5. Режим SERP
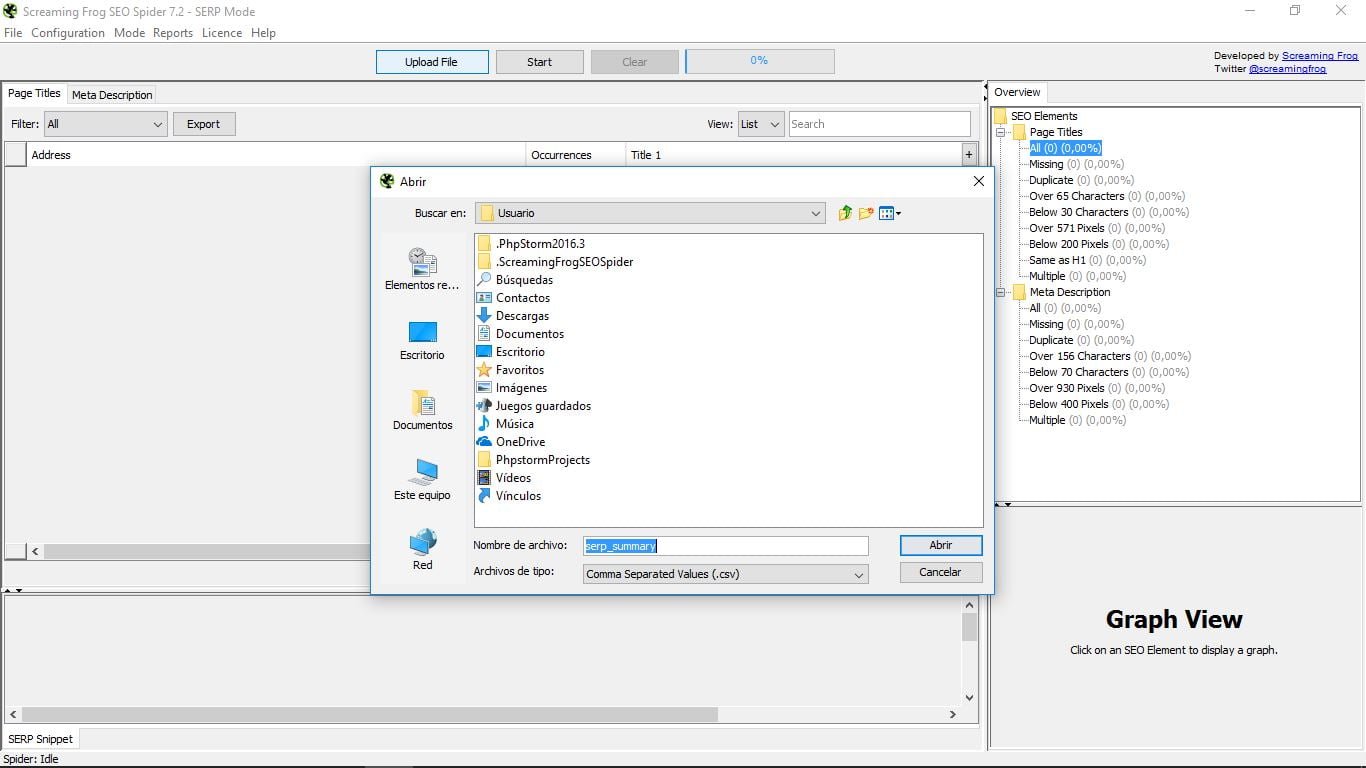
Цей третій варіант також вимагає навантаження з нашого боку, в даному випадку документ CSV з URL-адресами, які ми хочемо проаналізувати. Ми побачимо їх назву та метаописання. Решта функцій точно такі ж, як і в попередніх двох режимах.
6. Бонусний трек
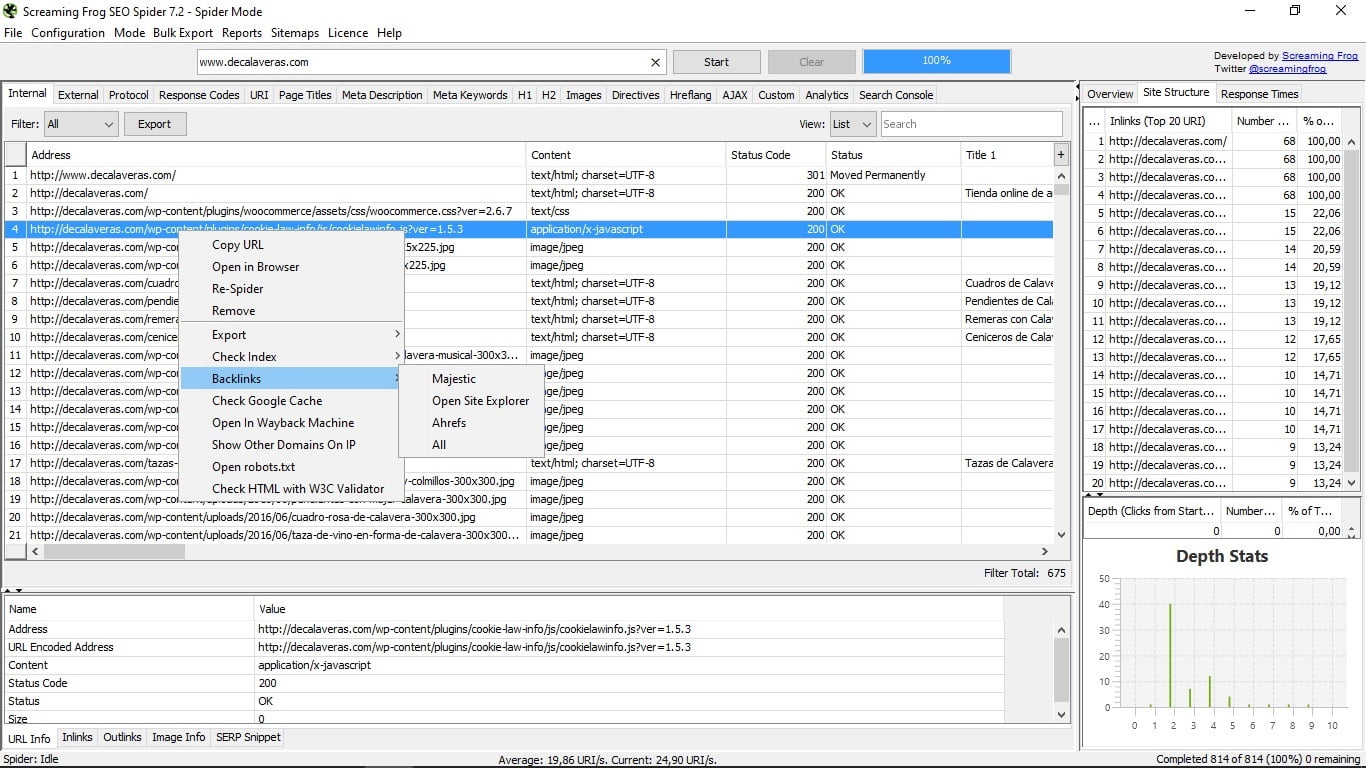
Маленька коробка трюк, в якій не всі падають. Якщо ви натискаєте правою кнопкою в будь-якому URL-адресі, у вас буде дуже корисне меню, яке дозволить вам:
- Скопіюйте URL-адресу
- Відкрийте його в браузері.
- Зробіть павука відстежувати його знову.
- Видалити його зі списку.
- Експортуйте інформацію про цю URL-адресу, її внутрішні посилання, зовнішні посилання, дані її зображень і реєстрацію шляху відстеження.
- Перевірте їх індексацію в Google, Yahoo, Bing або відразу.
- Перегляньте зворотні посилання на цю адресу через Majestic Seo, Open Site Explorer і інструменти Ahrefs.
- Перегляньте кеш цієї сторінки в Google.
- Відкрийте його в Wayback Machine, веб-сайті, який показує, як сторінка була в історичних записах, які ви архівували.
- Показувати інші домени, які знаходяться на тому ж IP-адресі, що й ця сторінка.
- Відкрийте файл robots.txt, який керує цією сторінкою.
- Перевірте можливі помилки html на сторінці з перевіркою інструменту W3C.
7. Інші інструменти Screaming Frog
Screaming Frog також пропонує інші інструменти, такі як Аналізатор файлів журналу , лог-аналізатор. Ця утиліта дозволяє завантажувати файли реєстру, виявляти сканування URL-адрес і аналізувати поведінку павука, тому це дуже корисно для SEO.
Він має безкоштовну версію, і ви можете придбати ліцензію, щоб користуватися всіма додатковими функціями. Але цей інструмент і ми побачимо його детально в іншому ексклюзивному підручнику.
Скажіть, чи є у вас питання щодо Screaming Frog Seo Spider? Це інструмент, який ви використовуєте?
Скажіть, чи є у вас питання щодо Screaming Frog Seo Spider?Це інструмент, який ви використовуєте?