 Товаров:
Товаров:
- Поиск контента Мы упоминали, что скрытое семантическое индексирование рассматривает шаблоны распределения...
- Завтрак в гиперпространстве
- Разложение по единственному значению
- <предыдущая следующий>
- Получите конкурентное преимущество сегодня
Поиск контента
Мы упоминали, что скрытое семантическое индексирование рассматривает шаблоны распределения слов (в частности, совпадение слов) по множеству документов. Прежде чем мы поговорим о математических основах, мы должны быть немного более точными о том, на какие слова смотрит LSI.
Естественный язык полон избыточностей, и не каждое слово, встречающееся в документе, имеет смысловое значение. На самом деле, наиболее часто используемые слова в английском слова, которые не несут содержания вообще: функциональные слова, союзы, предлоги, вспомогательные глаголы и другие. Первым шагом в выполнении LSI является отбраковка всех этих лишних слов из документа, оставляя только содержательные слова, которые могут иметь семантическое значение. Существует много способов определения слова содержимого - вот один рецепт для создания списка слов содержимого из коллекции документов:
- Составьте полный список всех слов, которые появляются в любом месте коллекции
- Откажитесь от статей, предлогов и союзов
- Откажитесь от общих глаголов (знать, видеть, делать, быть)
- Откажитесь от местоимений
- Откажитесь от общих прилагательных (большой, поздний, высокий)
- Откажитесь от вычурных слов (поэтому, тем не менее, пусть и т. Д.)
- Откажитесь от любых слов, которые появляются в каждом документе
- Откажитесь от любых слов, которые появляются только в одном документе
Этот процесс объединяет наши документы в наборы содержательных слов, которые мы затем можем использовать для индексации нашей коллекции.
Мышление в сетке
Используя наш список содержательных слов и документов, мы теперь можем сгенерировать матрицу терм-документов. Это причудливое название для очень большой сетки с документами, перечисленными вдоль горизонтальной оси, и словами содержания вдоль вертикальной оси. Для каждого содержательного слова в нашем списке мы пересекаем соответствующую строку и ставим «X» в столбце для любого документа, в котором появляется это слово. Если слово не появляется, мы оставляем этот столбец пустым.
Выполнение этого для каждого слова и документа в нашей коллекции дает нам в основном пустую сетку с редким разбросом X-es. Эта сетка отображает все, что мы знаем о нашей коллекции документов. Мы можем перечислить все слова содержимого в любом данном документе, выполнив поиск X-ов в соответствующем столбце, или мы можем найти все документы, содержащие определенное слово содержимого, просмотрев соответствующую строку.
Обратите внимание, что наше расположение двоичное - квадрат в нашей сетке либо содержит X, либо его нет. Эта большая сетка является визуальным эквивалентом общего поиска по ключевым словам, который ищет точные совпадения между документами и ключевыми словами. Если мы заменим пробелы и X-ы нулями и единицами, мы получим числовую матрицу, содержащую ту же информацию.
Ключевым шагом в LSI является декомпозиция этой матрицы с использованием метода, называемого декомпозицией по сингулярному значению. Математика этого преобразования выходит за рамки данной статьи (доступно строгое обращение Вот ), но мы можем получить интуитивное представление о том, что делает SVD, думая о процессе пространственно. Аналогия поможет.
Завтрак в гиперпространстве
Представьте, что вам любопытно, что люди обычно заказывают на завтрак в местном кафе, и вы хотите отобразить эту информацию в визуальной форме. Вы решаете проверить все заказы на завтрак из напряженного дня выходных и записать, сколько раз слова бекон, яйца и кофе встречаются в каждом заказе.
Вы можете построить график результатов своего опроса, настроив диаграмму с тремя ортогональными осями - по одной для каждого ключевого слова. Выбор направления произвольный - возможно, ось бекона в направлении x, ось яиц в направлении y и важная ось кофе в направлении z. Чтобы составить конкретный заказ на завтрак, вы подсчитываете вхождение каждого ключевого слова, а затем делаете соответствующее количество шагов вдоль оси для этого слова. Когда вы закончите, вы получите облако точек в трехмерном пространстве, представляющее все заказы на завтрак в этот день.
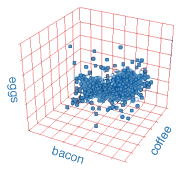
Если вы проведете линию от начала графика до каждой из этих точек, вы получите набор векторов в пространстве «бекон-яйца-кофе». Размер и направление каждого вектора говорит вам, сколько из трех ключевых элементов было в каком-либо конкретном порядке, а набор всех векторов, взятых вместе, говорит вам кое-что о том, какой завтрак предпочитают люди в субботу утром.
То, что показывает ваш график, называется термином пространство. Каждый заказ на завтрак формирует вектор в этом пространстве, его направление и величина определяются тем, сколько раз в нем появляются три ключевых слова. Каждое ключевое слово соответствует отдельному пространственному направлению, перпендикулярному всем остальным. Поскольку в нашем примере используются три ключевых слова, результирующее пространство терминов имеет три измерения, что позволяет нам его визуализировать. Легко видеть, что это пространство может иметь любое количество измерений в зависимости от того, сколько ключевых слов мы выбрали для использования. Если бы мы должны были вернуться к порядку и также записать случаи появления колбас, кексов и бубликов, мы бы получили шестимерное пространство терминов и шестимерные векторы документов.
Применение этой процедуры к реальной коллекции документов, где мы отмечаем каждое использование слова содержимого, приводит к пространству терминов со многими тысячами измерений. Каждый документ в нашей коллекции - это вектор, содержащий столько компонентов, сколько есть слов контента. Хотя мы не можем визуализировать такое пространство, оно построено точно так же, как причудливое место для завтрака, которое мы только что описали. Документы в таком пространстве, которые имеют много общих слов, будут иметь векторы, которые находятся рядом друг с другом, в то время как документы с несколькими общими словами будут иметь векторы, которые находятся далеко друг от друга.
Скрытое семантическое индексирование работает, проецируя это большое многомерное пространство на меньшее количество измерений. При этом ключевые слова, которые семантически похожи, будут сжаты вместе и больше не будут полностью различаться. Это размывание границ - это то, что позволяет LSI выйти за рамки простого соответствия ключевых слов. Чтобы понять, как это происходит, мы можем использовать другую аналогию.
Разложение по единственному значению
Представьте, что вы держите тропических рыб и гордитесь своим призовым аквариумом - настолько гордым, что хотите представить его фотографию в журнале Modern Aquaria для славы и прибыли. Чтобы получить наилучшее возможное изображение, вам нужно выбрать хороший угол, с которого можно сделать фотографию. Вы хотите убедиться, что как можно больше рыбы видно на вашей картинке, не будучи скрытыми другими рыбами на переднем плане. Вы также не захотите, чтобы все рыбы были сгруппированы вместе, а скорее подстрелили под углом, который показывает, что они хорошо распределены в воде. Поскольку ваш аквариум прозрачен со всех сторон, вы можете делать различные снимки сверху, снизу и со всего аквариума и выбирать лучший.
С математической точки зрения вы ищете оптимальное отображение точек в трехмерном пространстве (рыба) на плоскость (фильм в вашей камере). «Оптимальный» может означать много вещей - в данном случае это означает «эстетически приятный». Но теперь представьте, что ваша цель - максимально сохранить относительное расстояние между рыбами, чтобы рыбы на противоположных сторонах аквариума не накладывались друг на друга, чтобы выглядеть так, будто они находятся рядом друг с другом. Здесь вы будете делать именно то, что алгоритм SVD пытается сделать с гораздо более многомерным пространством.
Однако вместо преобразования 3-пространства в 2-пространство алгоритм SVD выходит на гораздо большие пределы. Типичный термин пространство может иметь десятки тысяч измерений и быть спроецирован на менее чем 150. Тем не менее, принцип точно такой же. Алгоритм SVD сохраняет как можно больше информации об относительных расстояниях между векторами документа, в то же время сворачивая их в гораздо меньший набор измерений. В этом коллапсе информация теряется, а слова содержания накладываются друг на друга.
Потеря информации звучит как плохая вещь, но здесь это благословение. То, что мы теряем, это шум от нашей исходной матрицы терминов-документов, выявляющий сходства, которые были скрыты в коллекции документов. Подобные вещи становятся более похожими, в то время как разные вещи остаются разными. Это редуктивное отображение - это то, что дает LSI, казалось бы, интеллектуальное поведение, позволяющее сопоставлять семантически связанные термины. Мы действительно используем свойство естественного языка, а именно то, что слова с похожим значением имеют тенденцию встречаться вместе.
<предыдущая следующий>
Эта работа лицензирована под Лицензия Creative Commons , 2002 Национальный институт технологий в гуманитарном образовании , Для получения дополнительной информации свяжитесь с автор ,
Получите конкурентное преимущество сегодня
Ваши главные конкуренты годами инвестировали в свою маркетинговую стратегию.
Теперь вы можете точно знать, где они находятся, выбрать лучшие ключевые слова и отслеживать новые возможности по мере их появления.
Изучите профиль рейтинга ваших конкурентов в Google и Bing сегодня, используя SEMrush.
Введите ниже конкурирующий URL-адрес, чтобы быстро получить доступ к их истории платных и обычных результатов поиска - бесплатно.
Посмотрите, где они ранги и победить их!
Похожие
VISASVERSLAS.LTSEO и SEM показатели оценки работы более Как запятая
«Я знаю, это так тяжело, но ты должен продолжать, ну, как, идти! Ты должен выиграть это, как, ну, так, как, мы оба!» Это лайк когда персонаж, как, постоянно бросает слово «как» в свои предложения. Часто используемые персонажами-девочками-подростками, которые, например, немного тусклые ? И, как, конец каждого предложения, как, с восходящим Урок 5 - SEO - Оптимизация структуры HTML
... последний эпизод нашей серии SEO мы начали давать рекомендации по структуре хорошо оптимизированного сайта с точки зрения SEO Мы достигли структуры HTML-кода, которую мы продолжим сегодня. <Описание> Описание - это один из мета-тегов, которые также очень важны и имеют значение, аналогичное названию. Он содержит краткое изложение того, что подстраница. Конечно, должно быть как можно больше ключевых слов и тех, которые действительно встречаются в статье. В то же Узнайте, как работает SEO 2016
M Теперь мы учимся работать в SEO 2016. Работает ли поисковая система Google в 2016 году так же, как в 2015 году? Этот вопрос может быть немного важным, мы знаем, как блоггер. Работа поисковой системы Google в 2016 году остается такой же, как и в прошлом году, или как она выглядит? Поэтому, если вы чувствуете необходимость узнать больше о том, как работать, о работающей Что такое SEO оптимизация, как она работает?
... lt="Google, Bing, Yahoo, Yandex"> Как определяются позиции в поисковой системе? Действия по оптимизации SEO включают в себя внесение изменений в структуру сайта, содержания, ключевых слов и других менее важных вещей (внутренняя оптимизация SEO), а также внесение наиболее важных из них - построение ссылок (внешняя оптимизация SEO). Все эти действия необходимы для того, чтобы сканеры поисковых систем могли «читать» (индексировать) ваш сайт, воспринимая как оптимизировать SEO-блогспот
Теги заголовка - это первые слова, выделенные посетителями вашего сайта и поисковыми системами. По этой причине, если вы хотите оптимизировать SEO, то заголовок тега нельзя пропустить или то, что вы делаете, как на странице, так и за ее пределами, не будет работать оптимально. Чтобы лучше понять, как озаглавить SEO оптимизацию, вы можете узнать следующее обсуждение. Теги заголовка - это теги, которые есть в заголовке или субтитрах. Например, главы в учебнике. Вы увидите, что у каждой Как работает SEO Позиционирование в поисковых системах
Как мы видели в введение в веб-позиционирование В тот момент, когда мы запустили наш сайт электронной коммерции, нам бы хотелось, чтобы он хорошо отображался на странице результатов поиска, но, к сожалению, это не так. Как и в большинстве случаев, наше восхождение в естественном позиционировании начинается снизу , и прежде чем приступить к приключению, нам нужно знать, как работает Как работает аудит контента и почему сейчас самое подходящее время для начала
... по колено в аудите контента, возможно, вы слышали, что они скучные и утомительные, но они того стоят - очевидно, тот тип задач, который мы ненавидим больше всего. Тем не менее, это то, что вы должны сделать, и это в конечном итоге окупится. В этом году Google во время своих изменений дал понять, что они находят способы оценить качество и актуальность контента. Это делает аудит контента в этом году более важным, чем когда-либо. Сделайте несколько глубоких вдохов, потому что чем раньше вы начнете, Что такое SEO и как оно помогает онлайн-бизнесу?
В этой статье специалист по SEO Георгий Георгиев из Ganbox расскажет вам, что такое SEO, что изменилось за последние годы и чего можно достичь с его помощью в пользу вашего бизнес-сайта. Мы начнем с нескольких вводных понятий и терминов. SEO - это процесс поисковой оптимизации (Google, Bing, Yandex и т. Д.), Часто используемый на болгарском языке как «SEO оптимизация». По мнению экспертов из Ganbox цель заключается Пример из практики: США Объявления Компания
... lt="Летом 2017 года их органический трафик резко упал, поэтому они обратились к нам за помощью"> Это показывает трафик с 1 апреля 2017 года по 22 октября 2017 года, когда мы впервые связались с этой компанией. В этот день трафик снизился до 1245 посетителей Google. До массового падения сайт посещал в среднем около 4500 посетителей в день. Наш Аудит Как всегда, первое, что мы сделали, - мы провели аудит Ir Что такое Amazon SEO? Amazon SEO Как ...
Хотите устранить своих противников с помощью Amazon SEO и увеличить свои продажи с помощью Amazon, которая является одной из крупнейших структур в цифровом мире? Улучшив видимость вашего продукта, вы можете разместить свои страницы Amazon в первую очередь в поисковой выдаче. Amazon SEO позволяет вашим страницам Amazon занимать первое место в результатах поиска Google. Ваши потенциальные клиенты, которые ищут ключевые слова в ваших продуктах Amazon, посетят ваш
Комментарии
Net/ </ link> <language> ru </ language> < ?net/ </ link> <language> ru </ language> < ? php # Это всего лишь пример # На самом деле вам нужно убрать лишние черты из текстовых полей, экранировать html-сущности и т. д. $ db = connectDatabase (); $ query = mysql_query ('SELECT `title`,` description`, `date` FROM` items` ORDER BY `id` DESC LIMIT 10', $ db); while ($ item = mysql_fetch_assoc ($ query): echo "<title> {$ item ['title']} </ title> <pubDate> {$ item ['date']} </ Ранее мы уже обсуждали, что такое SEO и как он работает, но что делать, если вы хотите улучшить свой SEO-рейтинг?
Ранее мы уже обсуждали, что такое SEO и как он работает, но что делать, если вы хотите улучшить свой SEO-рейтинг? Существует несколько способов улучшить положение вашего сайта в результатах поиска Google. Если вы только начинаете использовать SEO и хотите знать, с чего начать, или вы уже некоторое время занимаетесь этим и задаетесь вопросом, почему вы не видите значительных улучшений, мы вас обеспечим. Что такое Pogo Stick, что такое LSI, как увеличивается показатель отказов и как выполняется анализ обратных ссылок?
Что такое Pogo Stick, что такое LSI, как увеличивается показатель отказов и как выполняется анализ обратных ссылок? Этот человек, возможно, получил университетское образование, или SEO обучение возможно, взял. Если вы скажете, что будете использовать такие методы, как пакеты обратных ссылок, вас могут оштрафовать. 100% гарантированное ключевое слово, результаты на первой странице или в верхнем ряду, если этого Мы всегда надеемся, что вы, ребята, расскажете нам, как улучшить работу, и дадите нам отзывы о наших инструментах, поэтому расскажите, что вы думаете о новом инструменте ранжирования SEO?
Мы всегда надеемся, что вы, ребята, расскажете нам, как улучшить работу, и дадите нам отзывы о наших инструментах, поэтому расскажите, что вы думаете о новом инструменте ранжирования SEO? Вам нравится новая версия, и как вы относитесь ко всем изменениям, которые мы внесли? Также следите за обновлениями, новая модель ценообразования появится раньше, чем вы думаете. Завтра мы позволим вам прочитать все об этом. Как можно обещать определенные позиции, если никто не знает, как работает поисковая система Google и как один фактор влияет на другие?
Как можно обещать определенные позиции, если никто не знает, как работает поисковая система Google и как один фактор влияет на другие? Некоторые веб-сайты скрывают исходящие ссылки и ссылки на веб-сайты клиентов с совершенно неадекватных веб-сайтов. Это очень красивый пример - ссылки на SEO-сайт, скрытые в нижнем колонтитуле другого сайта. Мудро? Да, но есть шанс получить штраф Google - поздравляю! Мы могли бы говорить о SEO весь день, но сегодня мы просто расскажем, что такое SEO вне сайта?
Мы могли бы говорить о SEO весь день, но сегодня мы просто расскажем, что такое SEO вне сайта? По сути, SEO на месте - это вся поисковая оптимизация, которую вы выполняете на своем собственном сайте, то есть на собственном контенте. Вне сайта, вы рассматриваете все, что возвращается на ваши сайты. Таким образом, весь трафик поступает, будь то гостевой блог, статьи, даже события, размещенные на других сайтах, все, что возвращается на ваш сайт и обеспечивает видимость домена с других сайтов, Gt;>> Хотите узнать, как масштабировать результаты поиска?
gt;>> Хотите узнать, как масштабировать результаты поиска? Откройте для себя курс по маркетингу в поисковой системе Ninja Academy, онлайн-формула + практический класс в Милане (по желанию): учебный курс высокого уровня, предназначенный для обучения участников стратегиям и основным навыкам, которые должны быть достигнуты клиентами, и качественным перспективам. Вам интересно, как мы любим агентство интернет-маркетинга подумайте о поисковой оптимизации и как мы можем применить это на вашем сайте?
gt;>> Хотите узнать, как масштабировать результаты поиска? Откройте для себя курс по маркетингу в поисковой системе Ninja Academy, онлайн-формула + практический класс в Милане (по желанию): учебный курс высокого уровня, предназначенный для обучения участников стратегиям и основным навыкам, которые должны быть достигнуты клиентами, и качественным перспективам. Напомним, что было несколько страниц рейтинга / конкурентов с гораздо меньшей плотностью ключевых слов, чем остальные три, которые мы рассматривали, так что же мы сделали?
Напомним, что было несколько страниц рейтинга / конкурентов с гораздо меньшей плотностью ключевых слов, чем остальные три, которые мы рассматривали, так что же мы сделали? Начните с базовой линии среднего. Оказалось, 1,5% здесь . Как бы мне ни хотелось начать работу, Мари и я согласились, что 15 хорошо продуманных постов будут хорошим началом, и в зависимости от того, как рейтинг начнет сдвигаться, мы будем подгонять число выше или ниже по мере необходимости. [ Как мы можем убедиться, что мы там?
Как мы можем убедиться, что мы там? Ресурс, который все еще часто упускают из виду, Google My Business , эволюция того, что до недавнего времени было Google Places . Кто бы ни имел компанию, особенно если она небольшая, по всей вероятности, уже вступил в контакт с нами (также потому, что во многих ситуациях есть один из владельцев, который занимается практически всем, включая присутствие в Интернете); однако Но что, если вы все равно обнаружите, что результаты включения вашей страницы в китайских поисковых системах, таких как Baidu, не так много, как в Google?
Но что, если вы все равно обнаружите, что результаты включения вашей страницы в китайских поисковых системах, таких как Baidu, не так много, как в Google? Если это произойдет с вами, я считаю, что ваш веб-сервер, скорее всего, будет размещен за пределами Китая. В этом случае, вы все еще можете улучшить уровень включения страницы? Ответ - да. Сначала проверьте ваш сайт в Baidu Zhanzhang инструмент (Версия Baidu для веб-мастеров).
Часто используемые персонажами-девочками-подростками, которые, например, немного тусклые ?
2016. Работает ли поисковая система Google в 2016 году так же, как в 2015 году?
Работа поисковой системы Google в 2016 году остается такой же, как и в прошлом году, или как она выглядит?
Lt="Google, Bing, Yahoo, Yandex"> Как определяются позиции в поисковой системе?
Хотите устранить своих противников с помощью Amazon SEO и увеличить свои продажи с помощью Amazon, которая является одной из крупнейших структур в цифровом мире?
Net/ </ link> <language> ru </ language> < ?
Ранее мы уже обсуждали, что такое SEO и как он работает, но что делать, если вы хотите улучшить свой SEO-рейтинг?
Что такое Pogo Stick, что такое LSI, как увеличивается показатель отказов и как выполняется анализ обратных ссылок?
Что такое Pogo Stick, что такое LSI, как увеличивается показатель отказов и как выполняется анализ обратных ссылок?
Мы всегда надеемся, что вы, ребята, расскажете нам, как улучшить работу, и дадите нам отзывы о наших инструментах, поэтому расскажите, что вы думаете о новом инструменте ранжирования SEO?